Vision AI Dev Kit utilizing Azure Cognitive Services Face API for Face detection
| Summary |
|
This is a quick proof of concept integrating the power of Azure Cognitive Services in the cloud with initial real time object detection running on the intelligent edge device. This project builds on the basic features already installed in the Vision AI DevKit getting started Module. Using the default ML model for object detection, this project takes a screenshot when one or more people are detected in frame. It then sends the screenshot to the configured Azure Cognitive Services Face API using the provided Face API URL endpoint and subscription key for face detection results. |
| Implementation |
|
More details about the Face API can be found here. After detecting one or more people in frame a screenshot is taken and the image is sent via a https post request to url endpoint “detect”. Once the Face API receives the image it will return the following inference results: “Detect one or more human faces in an image and get back face rectangles for where in the image the faces are, along with face attributes which contain machine learning-based predictions of facial features. The face attribute features available are: Age, Emotion, Gender, Pose, Smile, and Facial Hair along with 27 landmarks for each face in the image.” The results are saved in a locally available json file and a subset are annotated onto the screenshot which is then saved locally. The results can be viewed using the following links: http://CameraIP:1080/media/Azure_Face_Api_Result.json http://CameraIP:1080/media/Azure_Face_Api_Result.jpg. |
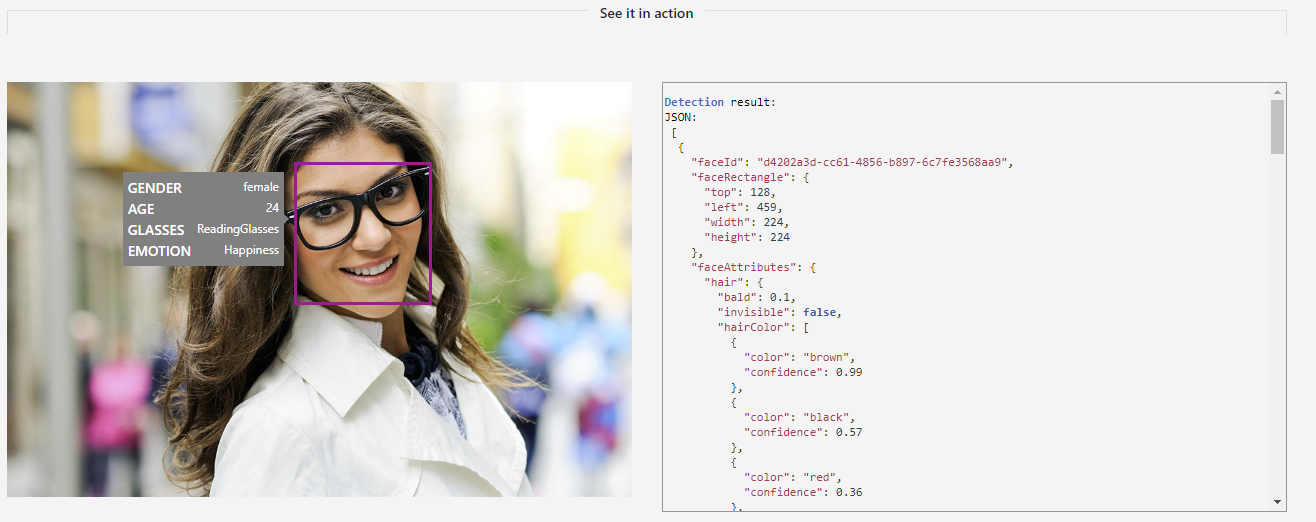 |
| Software and Services used | Hardware | |
|
|
| Repository |
|
Find all relevant information, including code, for full implementation of this product here. Users are always encouraged to innovate and continue to improve the functionality of current projects. |
| Future Improvements and Project Suggestions |
|
Like mentioned above this is a quick proof of concept integrating the power of Azure Cognitive Services in the cloud with initial inference running on the intelligent edge device. The Azure face API has many more features in addition to “detect” documented here. Using the above API documentation extending the features of this project should be straight forward. One example would be to verify the identity of the person in frame. |
| About the Creator |
 |
|
David Grob recently completed an Electrical Engineering Bachelor’s Specializing in Computer Engineering and is currently enrolled in an Electrical and Computer Engineering Master’s program at Georgia Tech. He has completed undergrad research at Seattle University spanning Computer Vision, data analytics automation, Machine Learning, and co-authored two well-received Conference Papers presented at IEEE International Conference on Data Mining (ICDM) and International Conference on Signal Processing Systems (ICPS)—November 2018.
You can find his publications for ICDM and ICPS here. |
Leave a comment