Schema design considerations for Azure Cosmos DB
Azure Cosmos DB stores data as schema-less JSON objects. The schema you intend to use needs to be managed or enforced by outside applications.
There are decisions in your Azure Cosmos DB design that need to be made before you create the database. Consider the following points when you create JSON objects:
-
Data modeling
-
Partition key
Data modeling
Before you store data, make sure your objects are stored in a logical way.
In a nonrelational database, data is stored denormalized and is optimized for queries and writes.
Consider the Contoso Pet Supplies models in a relational entity relationship diagram:
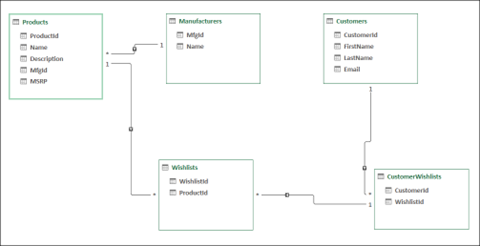
Notice that tables are organized by entities, and bridge tables are present to establish relationships between entities.
When you create documents for Azure Cosmos DB, consider the following questions:
-
How is this data accessed?
-
Are columns called together frequently in queries?
-
Are columns called together frequently in queries via JOINs? Keep in mind that the relational concept of JOINs doesn’t translate to the JOIN in Azure Cosmos DB.
-
Are columns updated together?
Sometimes entities translate 1-to-1 from relational to nonrelational. At other times, you’ll find that it makes more sense to embed entities. This scenario can occur when you embed the manufacturer within a product. For example, if you don’t use the manufacturer alone but use it only when you work with products. When you need to use JOINs in relational queries, you might need to denormalize the data. For example, when you pass along customer emails for wishlist notifications. The reason is because wishlist updates need to go to the customer.
This article gives guidance on Modeling data in Azure Cosmos DB.
Partition key decisions
The partition key stores objects of the same value together in the partition key. For example, if you want to categorize your products, you could store them in a separate container and partition them by category. Doing so would store products of the same category together in a logical partition. When determining what to use for the partition key, keep this guidance in mind:
- For read-heavy containers, use a field that is optimized for frequently run queries.
- For write-heavy containers, use a field with diverse data that balances the load.
When looking at models in the Contoso Pet Supplies project, we create a property called documentType to use as the partition key. A couple of exercises bring us to that decision:
-
We first look at our data to see what details are stored in our objects. If they all have to live in one container, what would the queries look like? There would be many queries filtered by object type.
-
We then view our data for how it loads in the database. The object type needs to be diverse enough to balance the load across partitions. It needs to ensure each value has a similar load and that no single value takes on a heavy load.
By setting /documentType as our partition key, we have a key that works well for our environment.