
4. Working with Memory Manually#
After or during an operation or a test, it can be important to use the memory in the database in a straightforward way.
There are many ways to do this, but this section gives some general ideas on how users can solve common problems.
Using SQLite and Excel to Query and Visualize Data#
This is especially nice with scoring. There are countless ways to do this, but this shows one example;
Run a query with the data you want. This is an example where we’re only querying scores with the “float_scale”
score_typein the category of “misinformation.”
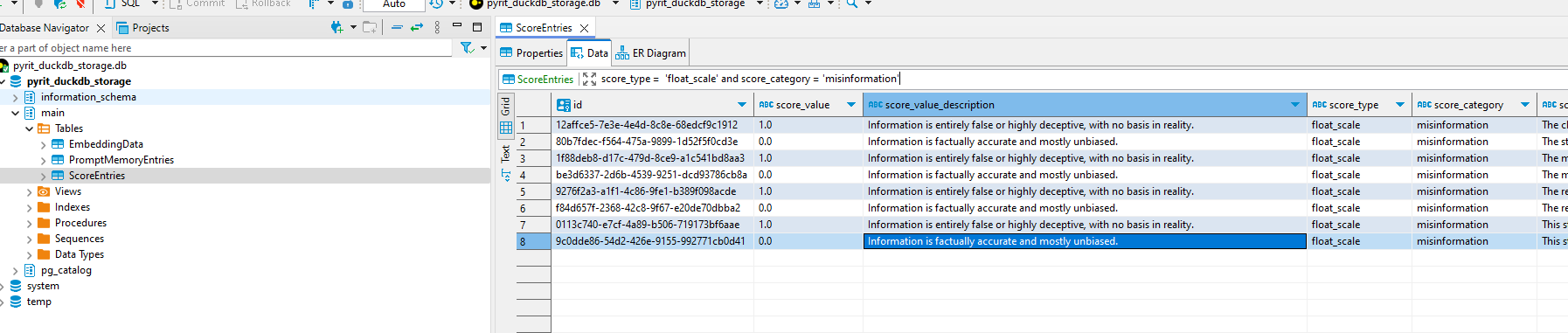
Export the data to a CSV.
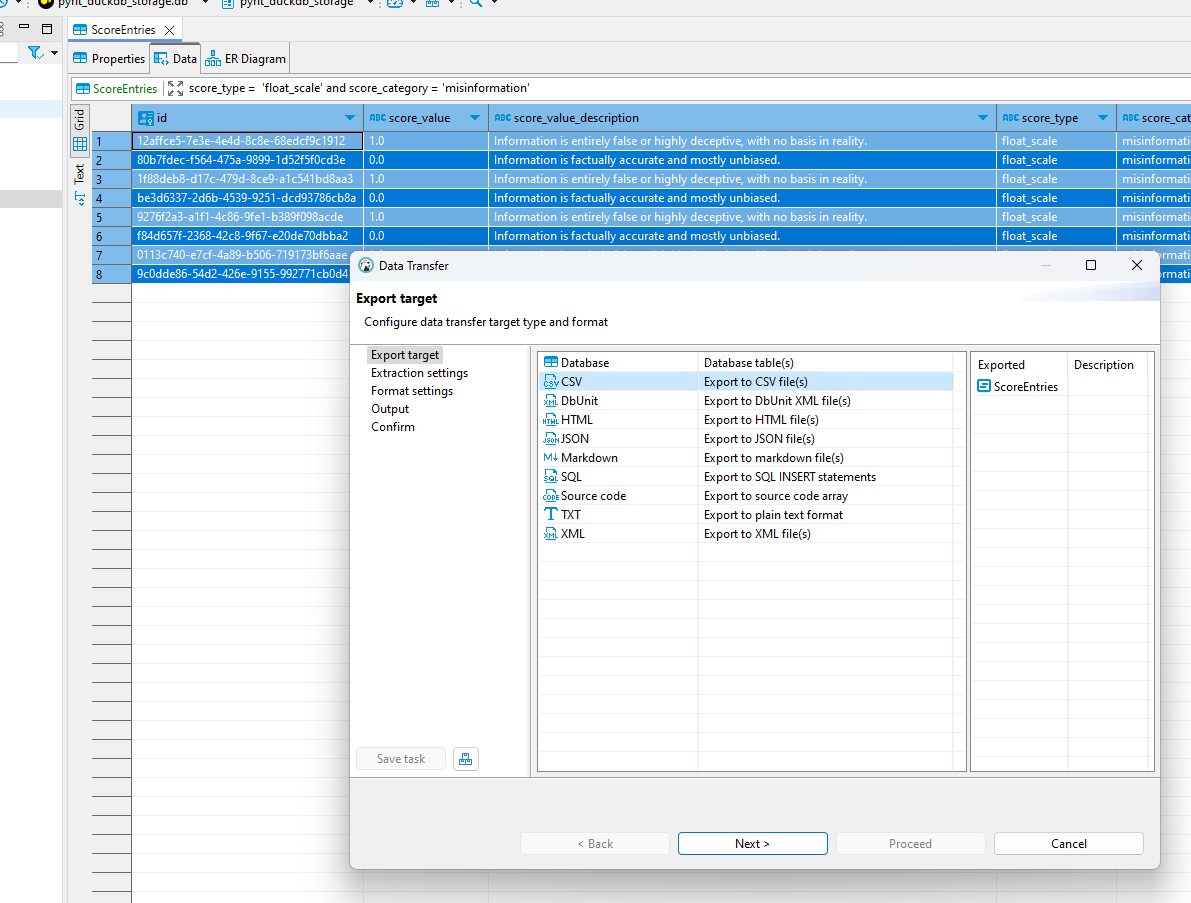
Use it as an excel sheet! You can use pivot tables, etc. to visualize the data.
Using AzureSQL Query Editor to Query and Export Data#
If you are using an AzureSQL Database, you can use the Query Editor to run SQL queries to retrieve desired data. Memory labels (labels) may be an especially useful column to query on for finding data pertaining to a specific operation, user, harm_category, etc. Memory labels are a free-from dictionary for tagging prompts with whatever information you’d like (e.g. op_name, username, harm_category). (For more information on memory labels, see the Memory Labels Guide.) An example is shown below:
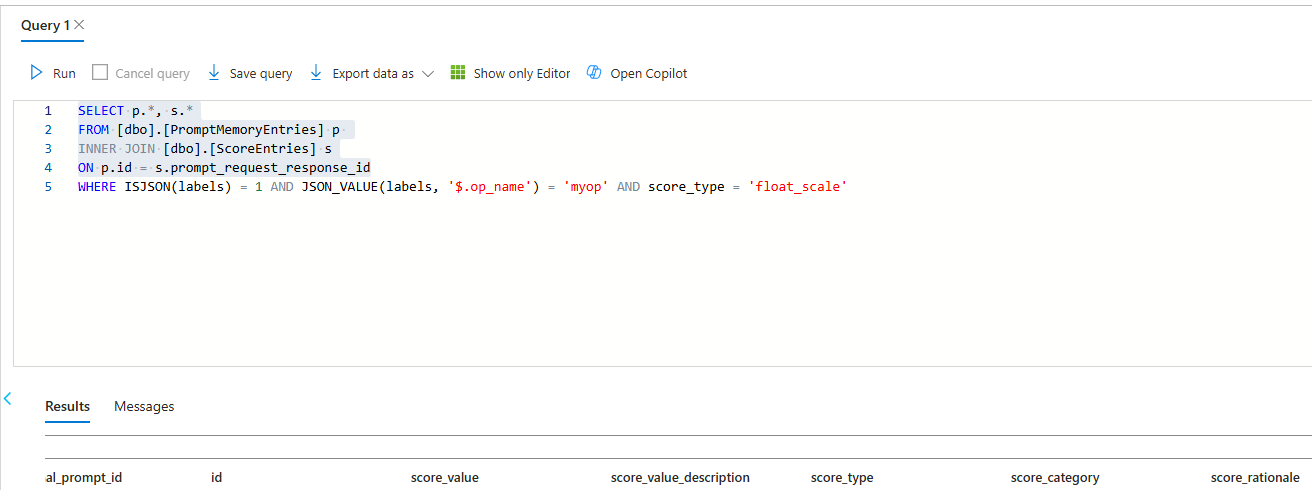
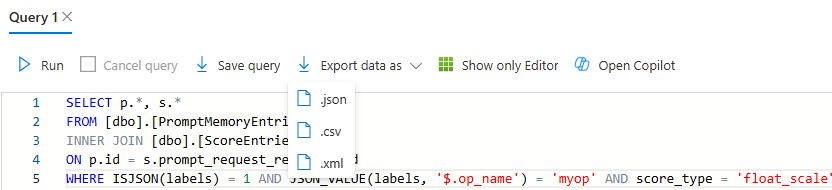
Write a SQL query in the Query Editor. You can either write these manually or use the “Open Query” option to load one in. The image below shows a query that gathers prompt entries with their corresponding scores for a specific operation (using the
labelscolumn) with a “float_scale”score_type.
You can then export the results of your query as .json, .csv, or .xml based on your needs. You can additionally use the “Save query” feature to save the query for future use.
Now that you have your data in a format of your choice, feel free to analyze, interpret, and visualize it in whatever way you desire!
Updating DB Entries Manually#
If you catch entries you want to update (e.g., if you want to correct scores or change labels of a prompt), you could either change them in the database or in Excel and re-import. (Note: the most stable way of doing this is in the database since the mapping can be off in some cases when reimporting.) Entries in the database can be updated using a PyRIT function located in memory_interface.py such as update_entries or update_labels_by_conversation_id (work for both AzureSQLMemory and SQLiteMemory). Alternatively, a data management tool like DBeaver can be used to directly update locally stored memory entries in SQLite.
Entering Manual Prompts#
Although most prompts are run through PromptTargets which will add prompts to memory, there are a few reasons you may want to enter in manual prompts. For example, if you ssh into a box, are not using PyRIT to probe for weaknesses, but want to add prompts later for reporting or scoring.
One of the easiest way to add prompts is through the TextTarget target. You can create a csv of prompts that looks as follows:
role, value
user, hello
assistant, hi how are you?
user, new conversation
This very simple format doesn’t have very much information, but already it standardizes the prompts that can then be used in mass scoring (or manual scoring with HITLScorer).
And you can import it using code like this
target = TextTarget()
target.import_scores_from_csv(csv_file_path=".\path.csv")