⭐Best practices and other insights
1. Is Anomaly detection the right approach?
Not all of the problems you'll find are solvable with anomaly detection. This implies some important things:
You need a clear and unambiguous definition of the problem you're trying to detect. It is also best if there are direct ways to measure it happening. Besides, you might need to relate the system behavior to a known model, such as human defined-rules , to detect a more complicated problem. If you have no model that describes how the system should behave, how do you know that your definition of a problem is correct?
-
Potential question you need to answer:
-
Human defined rules/Features How did you define your anomalies? Do you have sort of human-defined rules to recognize anomalies? Those rules could be used to guide the model if you have one. What features are used in your current approaches? We would like to know your featurization and selection process.
-
Label Data for experiments Will the label be provided, and how did you get those labels? In the first step, we hope you can provide us with data with labels that could be easier for us to validate and fine-tune the model efficiently.
-
Evaluation Criteria We usually want to analyze the difference between our model and your current model/method. Studying those differences could give us a rough estimation of the accuracy. Still, we want to know your opinion on the proposed evaluation criteria.
-
Expectation What do you expect from ML/DL models? In other words, what challenges are not well addressed by their existing approaches?
-
If you can get close to that, you might have a good shot at using anomaly detection to solve your problem.

2. Start small, iterate quickly
Instead of taking the entire data set, look at a subsample. It's more valuable if you have a size of a data set that allows you to work very quickly and try out different ideas. And then only over time, when you think you know this is the right thing and have to make more fine-grain decisions, can you move up to the thing.
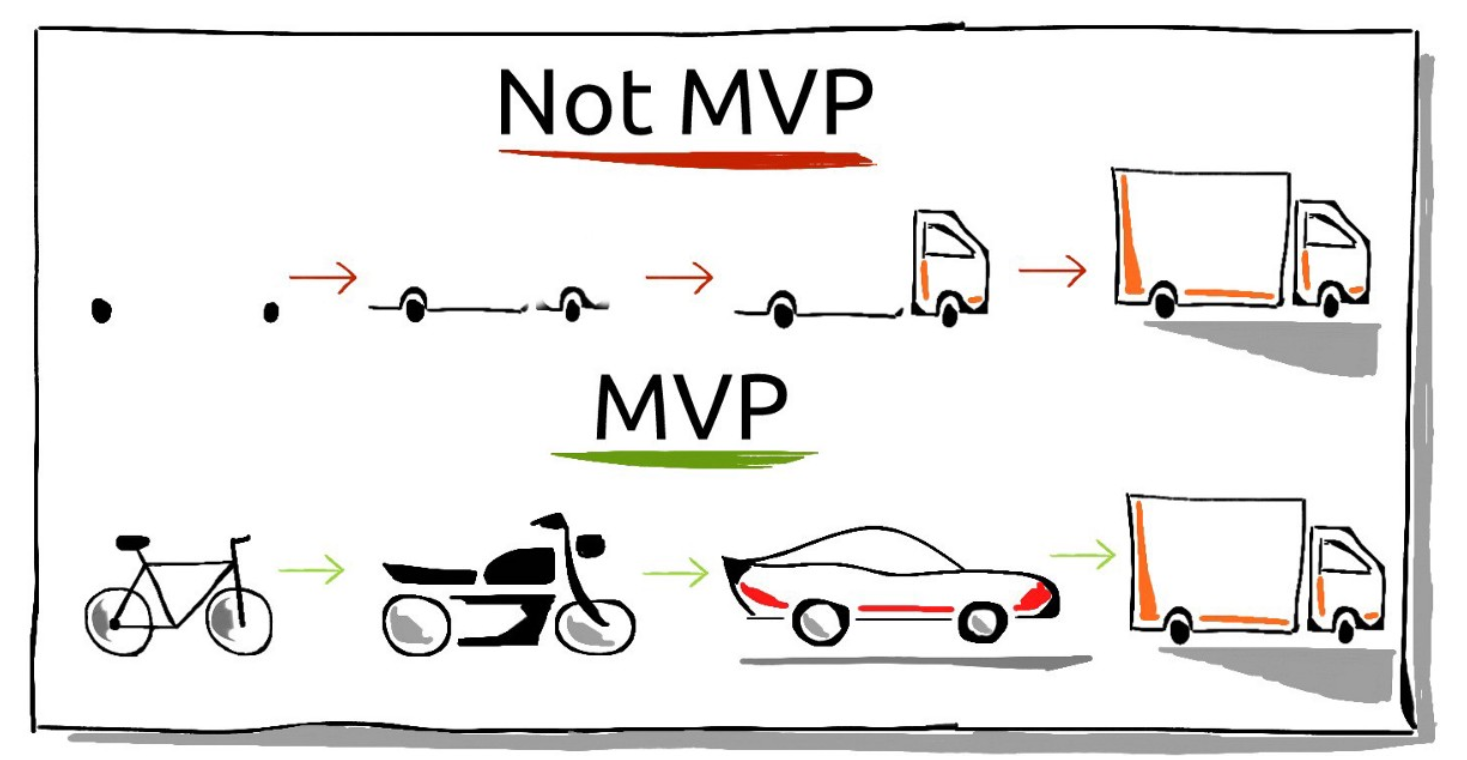
3. Choose a metric
When it comes to real-world or business-related problems, you really need to know what you want to achieve. So what is the metric? What kind of performance is the performance level you actually need? You should, beforehand, know the expected performance level that would be OK for the application so that you can also know if I need more data, is this already good enough, and so on, and how to measure it. And especially in some cases, it might also be very clear what the prediction and accuracy that you are looking for are.

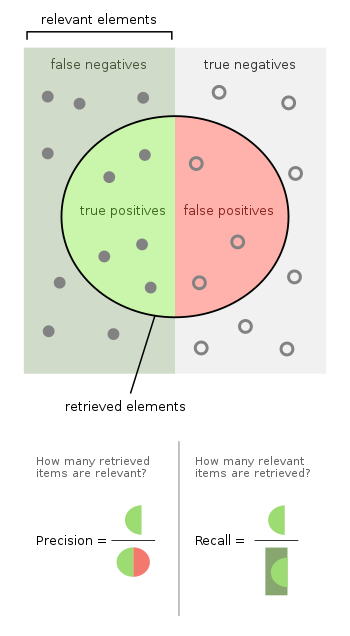
4. Evaluate properly
The labels and the evaluation metrics will help assess just how good the unsupervised models are at catching known patterns. Unsupervised learning systems are much harder to evaluate than supervised learning systems. Often, unsupervised learning systems are judged by their ability to catch known patterns. It's important to be mindful of this limitation as we proceed in evaluating the results. With time series data where you have highly interdependent data, you really have to make sure that you're testing on the right thing. You have to be really careful there to make sure that the estimate of the performance that you get from data analysis is the thing that you will also then see in reality.
5. Close the loop
Eventually you want to bring data analysis to production. On the upper right hand side, we have the data science part, and on the lower side is the engineering part. it's not a one-way road where you start with the data, you create your model, you bring it to production. But actually, the next round will be how can we improve the model? So you should definitely, from the very beginning, already think of this whole process like a bigger iteration workflow between production and data science.
6. Alert Selectively
Anomaly detection methods and models don't have enough context themselves to know if a system is actually anomalous or not. It's your task to utilize them for that purpose. On the flip side, you also need to know when to not rely on your anomaly detection framework. When a system or process is highly unstable, it becomes extremely difficult for models to work well. We highly recommend implementing filters to reduce the number of false positives. Some of the filters we've used include:
- Instead of sending an alert when an anomaly is detected, send an alert when N anomalies are detected within an interval of time.
- Suppress anomalies when systems appear to be too unstable to determine any kind of normal behavior.

Conclusions
Although it's easy to get excited about success stories in anomaly detection, most of the time someone else's techniques will not translate directly to your systems and your data. That's why you have to learn for yourself what works, what's appropriate to use in some situations and not in others.
Our suggestion, store the results, but don't alert on them in most cases. And keep in mind that the map is not the territory: the metric isn't the system, an anomaly isn't a crisis, three sigmas isn't unlikely, and so on.