⭐Preprocessing your data
Data can be challenging to deal with. This chapter will show you how to preprocess your data to Metrics Advisor for Equipment.
Metrics Advisor for Equipment uses your datasets with these steps below:
- To train a model
- To evaluate a model
- To conduct a streaming inference
1. Data format requirements
- One table/ file per asset.
- All sensors from that asset are represented in that one file/table.
2. Data schema requirements
Column mapping
Metrics Advisor for Equipment need a column mapping with your current dataset ; We use the default mapping strategy:
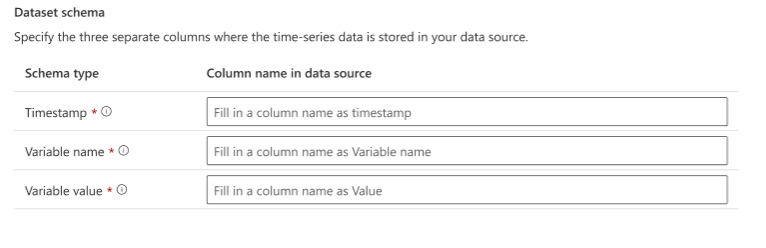
Metrics Advisor for Equipment three columns:
- The first column headers of the file include the
Timestampthat indicates the date and time. The timestamp column should contain date-time values in the yyyy-MM-ddTHH:mm:ss format and conform to ISO 8601. All timestamps passed to the service must be formatted as UTC timestamps. - The second column headers include the
Variable name. The variable name column should contain the name of the variable for each data point - The third column headers show the
Variable value.The value column should correspond to numerical metrics such as revenue, number of users, latency, and error rate.
| Timestamp(Date-Time) | Variable name(String) | Variable value(numeric) |
|---|---|---|
| 1/1/2020 0:05 | Sensor 1 | 2.0456 |
| 1/1/2020 0:10 | Sensor 2 | 6.4948 |
| 1/1/2020 0:15 | Sensor 3 | 4.2938 |
| 1/1/2020 0:20 | Sensor 2 | 4.3894 |
| 1/1/2020 0:25 | Sensor 1 | 5.4098 |
The easiest way to prevent problems with column headers is to take the following precautions: o Character length limit: 200 characters. o Valid characters: 0-9, a-z, A-Z, and _ (underscore). o Make sure that you don't have any duplicated column headers.
3. Data quality
:white_check_mark:Your dataset should contain time-series data that's generated from an industrial asset such as a pump, compressor, motor, and so on. Each asset should generate data from one or more sensors. The data that Metrics Advisor for Equipment uses for training should represent the asset's condition and operation.
:white_check_mark:We recommend that you remove unnecessary sensor data. With data from too few sensors, you might miss critical information. With data from too many sensors, your model might overfit the data and miss out on critical patterns.
Use these guidelines to choose the right data:
-
**Missing data: **In general, the missing value ratio of training data should be under 20%. Too much missing data may result in automatically filled values (usually linear or constant values) being learned as normal patterns. That may result in real (not missing) data points being detected as anomalies. Metrics Advisor for Equipment automatically fills in missing data (known as imputing). It does this by forwarding filling previous sensor readings. However, if too much original data is missing, it might affect your results.
-
Data granularity: Ensure each variable has at most one data point within each interval. For example, suppose that data from some sensors are being recorded every 1 minute and other sensors are recording every 5 minutes. In this case, set the data granularity to an interval of 1 minute. If your data granularity unit is minute, make sure that your data granularity is a multiple or factors of 60.
**Note: **Finding the right granularity is important. When data granularity is very high, you have more data, but it will be more "noisy," and as your data granularity goes down, it becomes tough to detect anomalies.
4. Data quantity
- Data size: Although Metrics Advisor for Equipment can ingest more than 50 GB of data, it can use only 7 GB with a model. Factors such as the number of sensors used, how far back in history the dataset goes, and the sample rate of the sensors can all determine how many measurements this amount of data can include.
- The minimum number of data points to train a model: The empirical rule is that you need to provide 15K or more data points (timestamps) per variable to train the model for good accuracy. However, in cases when you're not able to collect that much data, we still encourage you to experiment with less data and see if the compromised accuracy is still acceptable.
- The minimum number of data points to batch inference: At most 20K, at least 12 sliding window length.
- The minimum number of data points to near real time inference: At most 2880, at least 1 sliding window length. Detecting timestamps: from 1 to 10.
5. The state of the dataset
Once you have your data, you must establish how Metrics Advisor for Equipment will ingest it. Metrics Advisor for Equipment can look very different depending on how fast you need results or how much data goes into detecting an anomaly. To establish data ingestion, we'll consider two other states of the data: batch and streaming data. The data's state impacts the speed and accuracy of the anomaly detection algorithm(s).
- Batch data on a storage medium (e.g. a database or a data warehouse), and hence, the data processing speed does not have any bearing on data loss.
- Streaming data is typically characterized by the continuous and unbounded nature of inflowing data, where successive record chunks are sent simultaneously and in small sizes.