Making Azure Functions more “serverless”
Chris Anderson (Azure)
One of the principles we believe in most for Azure Functions is that we want you to be solving business and application problems, not infrastructure problems. That’s why we’ve invested so much in the functions runtime (language abstractions, bindings to services, and lightweight programming model) as well as our dynamically scaling, serverless compute model. Given that goal, one thing has always stuck out in our experience: the memory setting you set for each of your Function Apps. The memory setting always felt out of place. Finding the optimal setting required lots of trial and error on the part of our users, and we’ve heard a lot of feedback from users that it’s not something which people want to; that it doesn’t feel very serverless. That is why today, we’re announcing that we’re no longer requiring you to set the memory setting; Azure Functions, in the Consumption Plan, will automatically decide the right resources to have available and only charge you for what you use, not just time but also memory/cpu.
How does Azure Functions manage my resources?
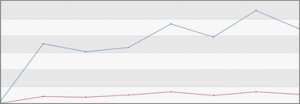
The Azure Functions platform collects a lot of data about how much utilization and resources your functions take when they execute. This enables us to make very accurate estimations of what you’ll need and distribute the work behind the scenes. The first time you run your Function, we’ll place it in the best a place possible, and should it appear to need more resources, we’ll find and allocate them automatically. We’ll continually be improving our algorithms to make sure that you have the best experience and that we do it as cost effectively as possible on our side. We have confidence that we can do this effectively because we’ve been modeling it with real data for a while now. Below is a graph with the actual numbers redacted, but y-axis is in linear GB-sec, and the base is 0; the x-axis is time. The blue line, on top, is the current amount of billable GB-sec. The red line, on bottom, is the new amount of billable GB-sec in our system. This means, overall, our customers are now paying for 5 times less GB-sec than they were before. Today, users can confidently write Functions without worrying about the right memory setting, knowing they’ll pay the least for their functions.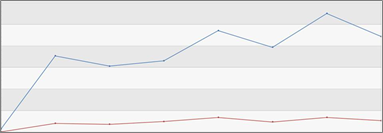
Do I need to rethink how I write my functions?
Overall, no, things work pretty much the same as before, with just one less setting to worry about. The same limits that applied before still apply: 1.5GB max memory and a 5-minute max execution time. The biggest impact that this change has is that you now are assured to be getting the right amount of resources and paying the least amount possible for your function executions.How to think about serverless computing
To help understand the impact of this change, let’s look at computing through an analogy. Imagine that compute works like shipping. Hosting your compute on prem is like buying a truck and paying the drivers yourself; you’re responsible for the hardware and the operational costs of operating that vehicle and the personnel. Infrastructure as a Service (IaaS - aka VMs) are like renting a truck, but still employing your own drivers; you’re no longer responsible for the hardware, but some operational costs (gas, maintenance, etc.) and the personnel costs still fall on you. Moving further up the hierarchy of compute, you can go with a fully managed Platform as a Service (such as Azure App Service) is like hiring a full-service company who will bring their truck and crew for you; you’re not responsible for the hardware or operational costs. But what if I want to just ship a bunch of small packages? Often it doesn’t make sense to pay by the truck, but rather by the package. This is where serverless computing stands to be transformative for how we build applications. We don’t have to focus on how shipping works because it’s not core to our business; we can focus instead on just getting the product to our customers. Each execution is like a package, and we pay for the size of the box. The change we’re making today, by removing set memory sizes, is made because compute while compute has similarities, it isn’t exactly like shipping physical objects. Knowing how much work is going to come in or what the right amount of compute (CPU/memory/IO) is not as simple as how tall and wide an object is; your resources required can change on each execution or even throughout an execution. Instead, we’ll now trigger your event and find the right size “package” for it, and only charge you for use, both time and resources.The future is even brighter, together
We’re committed to building the best serverless compute with the easiest experience and most powerful features. We want to know what we can make smoother. What questions do you have to ask yourself as you build functions? How can we make things easier, faster, better when you’re building your applications? Reach out to us in whatever way you prefer with issues, ideas, or questions:- Feedback portal: azure.com
- GitHub: azure/azure-functions
- Twitter: #AzureFunctions
- Stack Overflow: azure-functions tag