
Delve into Dynamic Resource Allocation, devices, and drivers on Kubernetes
Dynamic Resource Allocation (DRA) is often mentioned in discussions about GPUs and specialized devices designed for high-performance AI and video processing jobs. But what exactly is it?
Using GPUs in Kubernetes
Today, you need a few vendor-specific software components to even get started with a GPU node pool on Kubernetes - in particular, these are the Kubernetes device plugin and the GPU drivers. While the installation of GPU drivers makes sense, you might ask - why do we need a specific device plugin to be installed as well?
Since Kubernetes does not have native support for special devices like GPUs, the device plugin surfaces and makes these resources available to your application. The device plugin works by exposing the number of GPUs on a node, by taking in a list of allocatable resources through the device plugin API and passing this to the kubelet. The kubelet then tracks this set and inputs the count of arbitrary resource type on the node to API Server, for kube-scheduler to use in pod scheduling decisions.
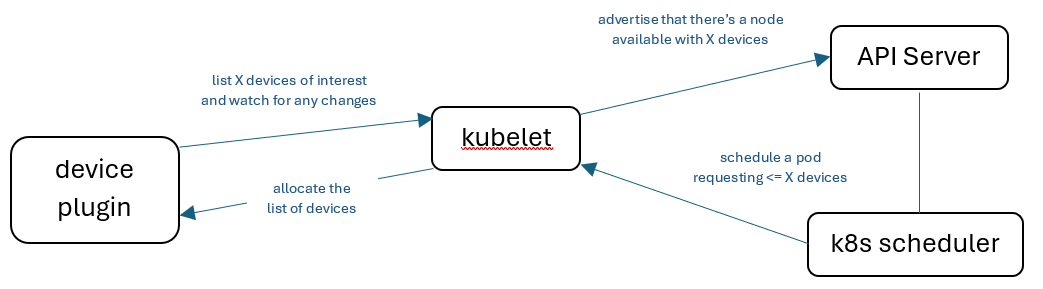
However, there are some limitations with this device plugin approach, namely:
- Granular selection of a node resource type can only be made using several node attributes and labels
- Without a feedback loop between the device plugin and kube-scheduler (in which suitable nodes identified for a schedulable pod are also “checked” by the plugin based on factors like node readiness conditions), pods can be scheduled on “unprepared” nodes that aren’t ready to accept new resources
As a result, DRA was introduced to address some of these limitations, by ensuring applications receive an adequate number of resources at the right time. The Dynamic Resource Allocation API generalizes the Persistent Volumes API for generic resources, like GPUs. It allows for resource adjustment based on real-time demand and proper configuration without manual intervention.
[!NOTE] Dynamic resource allocation is currently an alpha feature and only enabled when the DynamicResourceAllocation feature gate and the resource.k8s.io/v1alpha3 API group are enabled.
Let’s backtrack with a simpler scenario…I’m confused
Imagine that Kubernetes DRA is a working kitchen, and its staff is preparing a multi-course meal. In this example, the ingredients include:
- Pods: The individual dishes that need to be prepared
- Nodes: Various kitchen stations where the dishes are cooked
- API Server: The head chef, directing the entire operation
- Scheduler: The sous-chef, making sure each dish is cooked at the right station
- Resource Quotas: Portion sizes, ensuring each dish uses a specific amount of ingredients
- Horizontal Pod Autoscaler (HPA): Dynamic serving staff, adjusting the number of dishes served based on customer demand
The instructions for this DRA recipe are then to:
- Prep: Start by defining the recipes (Pods) and gathering all ingredients (resources like CPU and memory). Each recipe is assigned to a station (Node) by the head chef (API Server) through the sous-chef (Scheduler).
- Cooking: The stations (Nodes) start cooking the dishes (Pods) as directed. The head chef ensures everything is progressing smoothly and the dishes are being prepared according to the recipes.
- Portion Control: Use Resource Quotas to manage the portion sizes of each dish. This ensures that no single dish uses up too many ingredients, maintaining a balanced kitchen.
- Dynamic Serving: The HPA acts like a waiter, monitoring the number of customers (resource usage metrics) and adjusting the number of dishes prepared (Pod count) dynamically. If more customers arrive, more dishes are prepared; if the demand decreases, fewer dishes are made.
- Serving the Meal: The kitchen operates efficiently, with each dish receiving the right amount of attention and resources needed to ensure a delightful dining experience for the customers.
Just like in a restaurant kitchen, Kubernetes DRA makes sure your applications (dishes) get the right number of resources (ingredients) at the right time, providing an efficient resource management experience in the complex environment.
Now, we can dig into the nitty-gritty
DRA involves several key components to efficiently manage resources within a cluster, shown in the following sample resource driver:
apiVersion: resource.k8s.io/v1alpha3
kind: DeviceClass
name: resource.example.com
spec:
selectors:
- cel:
expression: device.driver == "resource-driver.example.com"
---
apiVersion: resource.k8s.io/v1alpha1
kind: ResourceClaimTemplate
metadata:
name: gpu-template
spec:
spec:
resourceClassName: resource.example.com
–--
apiVersion: v1
kind: Pod
metadata:
name: pod
spec:
containers:
- name: container0
image: gpuDriverImage
command: ["cmd0"]
resources:
claims:
- name: gpu
- name: container1
image: gpuDriverImage
command: ["cmd0"]
resources:
claims:
- name: gpu
resourceClaims:
- name: gpu
source:
resourceClaimTemplate: gpu-template
Adapted from: DRA for GPUs in Kubernetes
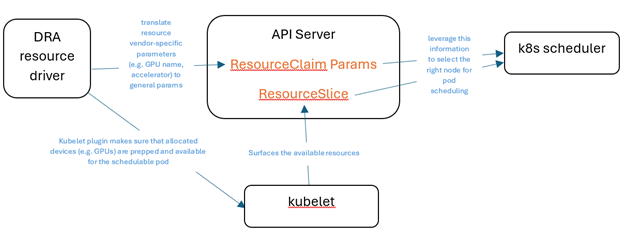
Here’s what each of the components are:
| Component | What does it do? |
|---|---|
| Resource Claims and Templates | ResourceClaim API allows workloads to request specific resources, such as GPUs, by defining their requirements and a ResourceClaimTemplate helps in creating these claims automatically when deploying workloads |
| Device classes | Predefined criteria for selecting and configuring devices. Each resource request references a DeviceClass |
| Pod scheduling context | Coordinates pod scheduling when ResourceClaims need to be allocated and ensures that the resources requested by the pods are available and properly allocated |
| Resource slices | Publish useful information about available CPU, GPU, memory resources in the cluster to help manage and track resource allocation efficiently |
| Control plane controller | When the DRA driver provides a control plane controller, it handles the allocation of resources in cooperation with the Kubernetes scheduler. This ensures that resources are allocated based on structured parameters |
The example above demonstrates GPU sharing within a pod, where two containers get access to one ResourceClaim object created for the pod.
The Kubernetes scheduler will try multiple times to identify the right node and let the DRA resource driver(s) know that the node is ready for resource allocation. Then the resourceClaim stages record that the resource has been allocated on a particular node, and the scheduler is signaled to run the pod. (This prevents pods from being scheduled onto “unprepared” nodes that cannot accept new resources.) Leveraging the Named Resources model, the DRA resource driver can specify:
- How to get a hold of a specific GPU type, and
- How to configure the GPU that has been allocated to a pod and assigned to a node.
In the place of arbitrary resource count, an entire object now represents the choice of resource. This object is passed to the scheduler at node start time and may stream updates if resources become unhealthy.
Pulling this all together, the key components of DRA look like:
Seeing DRA in action
Now, let’s see how the open-source k8s DRA driver works with NVIDIA GPUs on a Kubernetes cluster, specifically how it can provide:
- Exclusive access to a single GPU when multiple pods ask for it,
- Shared access within a pod with multiple containers, or
- Shared access across pods requesting that single GPU.
[!NOTE] The following is an experimental demo of the first scenario on a local Kind cluster; the open-source k8s DRA resource driver is under active development and not yet supported for production use on Azure Kubernetes Service.
We’ll start by creating a cluster having a provisioned GPU node with a Standard_NC4as_T4_v3 (4 vCPUs, 28 GiB memory) instance on Ubuntu Linux 24.04 and a 64GB system disk size.
After loading the "nvcr.io/nvidia/cloud-native/k8s-dra-driver:v0.1.0" image (that installs the control plane controller and kubelet plugin components) and confirming the Running status:
NAME READY STATUS RESTARTS AGE
nvidia-dra-driver-k8s-dra-driver-controller-7d47546f78-wrtvc 1/1 Running 0 7s
nvidia-dra-driver-k8s-dra-driver-kubelet-plugin-g42c9 1/1 Running 0 7s
We’ll apply the sample gpu-test1 demo script written by Kevin Klues from NVIDIA:
kubectl apply --filename=demo/specs/quickstart/gpu-test1.yaml
namespace/gpu-test1 created
pod/pod1 created
pod/pod2 created
The Standard_NC4as_T4_v3 VM has only one GPU, so in this scenario two pods are requesting exclusive access to the GPU. One pod will be scheduled and one will remain pending, with statuses looking like:
kubectl get pod -A
---
NAMESPACE NAME READY STATUS RESTARTS AGE
gpu-test1 pod1 1/1 Running 0 4s
gpu-test1 pod2 0/1 Pending 0 4s
...
...
---
kubectl describe pod -n gpu-test1 pod2 | less
---
Name: pod2
...
Status: Pending
...
Conditions:
Type Status
PodScheduled False
Volumes: ...
...
Events:
Type Reason Age From Message
---- ------ --- ---- -------
Warning FailedScheduling 23s (x2 over 25s) default-scheduler 0/2 nodes are available: 1 cannot allocate all claims...
---
Let’s say we delete pod1. Now, pod2 will get exclusive access to the single GPU:
kubectl delete pod -n gpu-test1 pod1
kubectl get pod -A
---
NAMESPACE NAME READY STATUS RESTARTS AGE
gpu-test1 pod2 1/1 Running 0 56s
...
...
Through this example and many others, we see how the kube-scheduler is told whether a GPU is fully committed to one workload or split across many workloads. Through further development of such DRA resource drivers, we can start to create fine-grained configurations to share GPU state across containers or pods, or even leverage multi-instance GPU (MIG) efficiently for AI, HPC, and GPU workloads!
Acknowledgements
Huge thanks to Alex Benn from the AKS team for testing and validating this DRA demo!