
Limitless Kubernetes Scaling for AI and Data-intensive Workloads: The AKS Fleet Strategy
Scaling Kubernetes for AI and Data-intensive Workloads: The AKS Fleet Strategy
With the fast-paced advancement of AI workloads, building and fine-tuning of multi-modal models, and extensive batch data processing jobs, more and more enterprises are leaning into Kubernetes platforms to take advantage of its ability to scale and optimize compute resources. With AKS, you can manage up to 5,000 nodes (upstream K8s limit) in a single cluster under optimal conditions, but for some large enterprises, that might not be enough.
Introducing AKS Fleet Manager: An Alternative Approach for High Scale
While you can opt to scale your node pools out within a single cluster, there are some challenges that you might encounter, including but not limited to Kubernetes control plane scaling limits (e.g., kube-apiserver bottlenecks, etcd performance, pod and container limits) and even cloud providers’ subscription, region, and/or resource limits.
That is why here at AKS, we believe taking a different approach might be worth exploring. Rather than scaling out to tens of thousands of nodes within a single cluster, we think scaling out to tens or even hundreds of clusters may be a more efficient approach, especially when leveraging the AKS Fleet Manager feature which was first announced in October 2022 and is powered by the KubeFleet project recently donated to the CNCF Sandbox. The reason people often didn’t want to approach it this (multi-cluster) way is because they saw more clusters as more operational burden, with Azure Kubernetes Fleet Manager and AKS, that’s no different than more nodes in a cluster.
With AKS Fleet Manager, you can unlock true limitless scalability by leveraging its ability to aggregate numerous AKS clusters for vast node provisioning tailored to your extensive AI training/serving and Data processing needs.
- Limitless Scalability: By grouping numerous AKS clusters into a single fleet, we enable practically limitless scalability. Need 100,000 nodes for your AI training tasks? Azure Kubernetes Fleet Manager makes this achievable.
- Reduced Blast Radius for Failures: A multi-cluster fleet significantly minimizes downtime risks. Failures remain isolated to individual clusters, preserving the stability of your overall system.
- Flexible Capacity Across Regions: Fleet Manager offers a flexible multi-region distribution of workloads that safeguards against capacity shortfalls.
Proof in Practice: Our 70,000 Node Demonstration
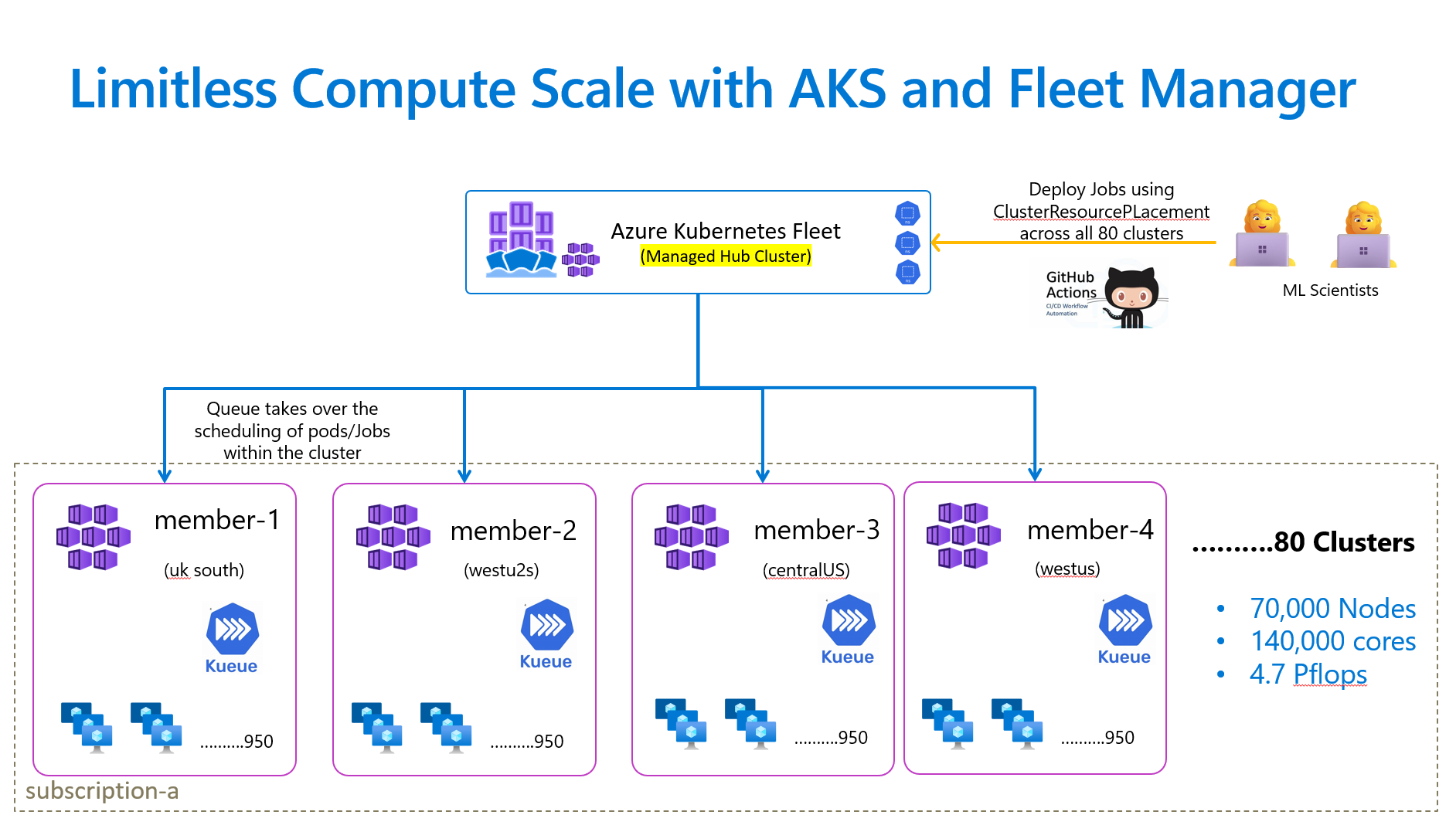
To validate our approach and showcase real-world performance, we recently executed an experiment with Kueue and AKS Fleet Manager to execute batch jobs, which yielded remarkable results. Here are some of the highlights:
- 80 Clusters: Deployed within a single fleet managed by AKS Fleet Manager.
- 70,000 Nodes: Distributed across six geographic regions, effortlessly supporting complex AI-like workloads.
- 140,000 cores delivering 4.7 pFLOPS of performance.
- Robust Scheduling: Leveraged Kueue and Fleet’s multi-cluster resource placement to efficiently schedule and operate workloads seamlessly across all clusters.
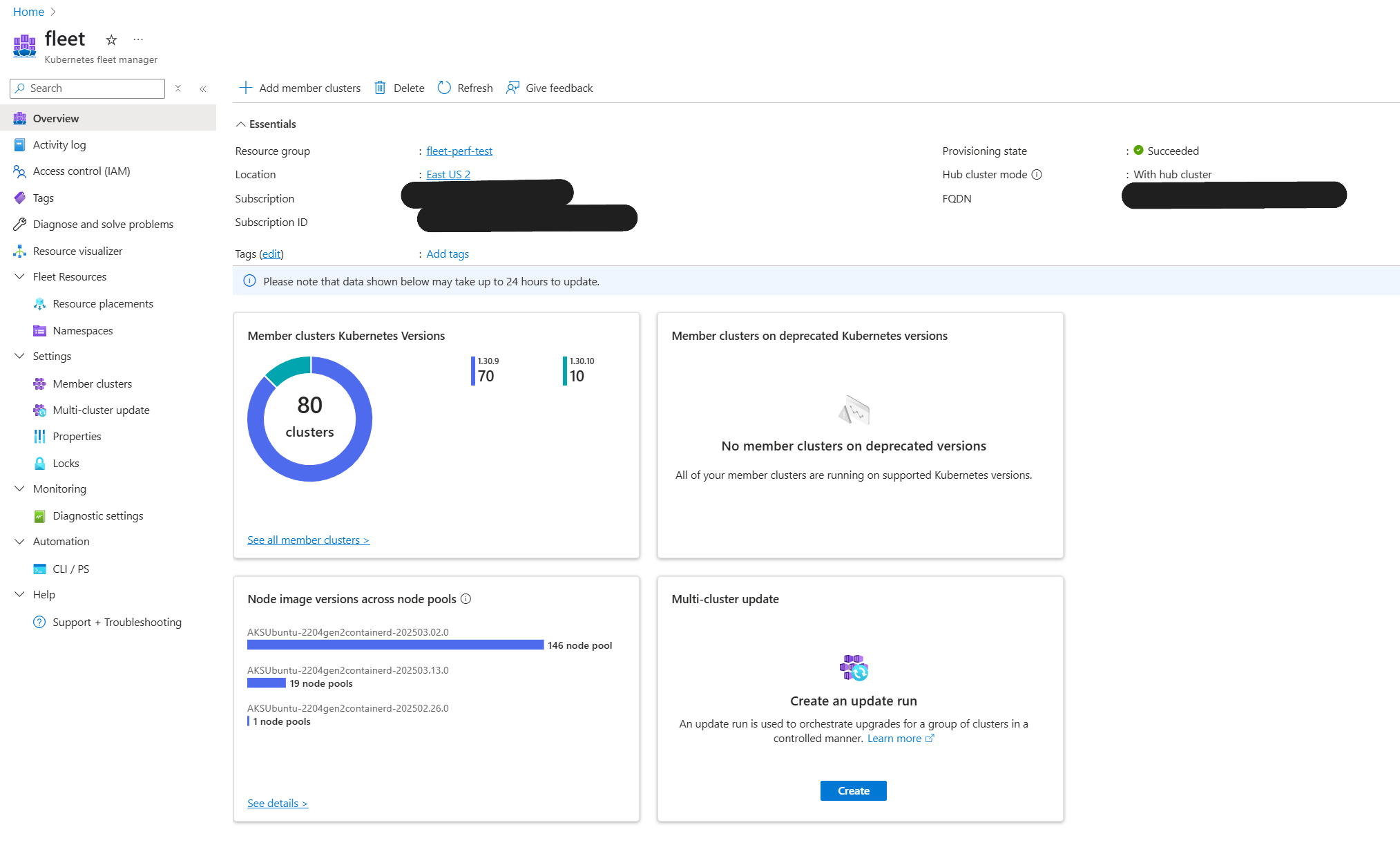
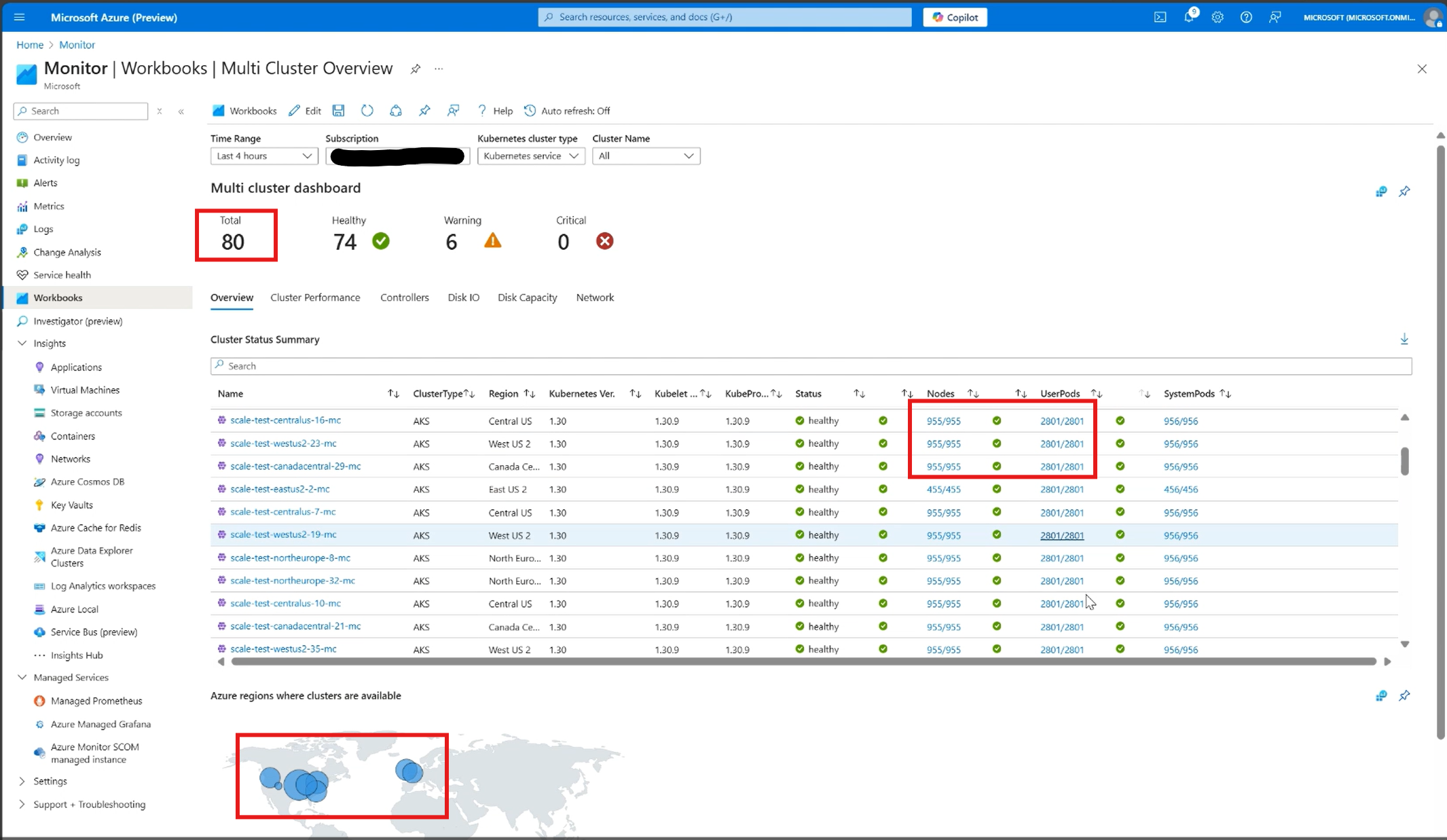
This demonstration highlights AKS’ commitment to not just meeting but exceeding customer expectations for scale, stability, and operational ease.
How to Deploy a Batch System Using Kueue with Fleet: A Step-by-Step Guide
1. Enable Kueue on Fleet
To enable Kueue in your fleet environment, you’ll need to install Kueue on your Member Clusters and the required CustomResourceDefinitions (CRDs) on your Hub Cluster.
a. Install Kueue on Individual Member Clusters
Before proceeding with the installation, keep in mind that you’ll need to switch to the context of the member cluster you want to install Kueue on. This is because Kueue needs to be installed and managed individually within each cluster, and you need to ensure that you’re interacting with the correct cluster when applying the necessary configurations.
VERSION=VERSION
kubectl apply --server-side -f \
https://github.com/kubernetes-sigs/kueue/releases/download/$VERSION/manifests.yaml
Replace VERSION with the latest version of Kueue. For more information about Kueue versions, see Kueue releases.
b. Install CRDs on Hub Cluster
Next, you will need to install the necessary CRDs on the hub cluster. Installing the CRDs here allows the hub cluster to properly handle Kueue-related resources. Please note, for demonstration purposes, we will only be installing the CRDs for ResourceFlavor, ClusterQueue, and LocalQueue.
Make sure you have switched to the context of your hub cluster before proceeding with the installation.
kubectl apply -f https://github.com/kubernetes-sigs/kueue/blob/main/config/components/crd/bases/kueue.x-k8s.io_clusterqueues.yaml
kubectl apply -f https://github.com/kubernetes-sigs/kueue/blob/main/config/components/crd/bases/kueue.x-k8s.io_localqueues.yaml
kubectl apply -f https://github.com/kubernetes-sigs/kueue/blob/main/config/components/crd/bases/kueue.x-k8s.io_resourceflavors.yaml
# Check CRDs are installed
kubectl get crds
2. Deploy a Batch System
With your Kueue-enabled fleet environment set up, you’re ready to deploy your batch system. Create the following resources on your hub cluster:
ResourceFlavor
A ResourceFlavor is an object that represents the variations in the nodes available in your cluster by associating them with node labels and taints.
apiVersion: kueue.x-k8s.io/v1beta1
kind: ResourceFlavor
metadata:
name: default-flavor
ClusterQueue
A ClusterQueue is a cluster-scoped object that oversees a pool of resources, including CPU, memory, and GPU. It manages ResourceFlavors, sets usage limits, and controls the order in which workloads are admitted.
apiVersion: kueue.x-k8s.io/v1beta1
kind: ClusterQueue
metadata:
name: cluster-queue
spec:
namespaceSelector: {}
queueingStrategy: BestEffortFIFO
resourceGroups:
- coveredResources: ["cpu", "memory", "ephemeral-storage"]
flavors:
- name: "default-flavor"
resources:
- name: "cpu"
nominalQuota: 4000
- name: "memory"
nominalQuota: 10000Gi
- name: "ephemeral-storage"
nominalQuota: 10000Gi
Namespace
The LocalQueue and Job require a namespace to be specified. This will also be used in your ClusterResourcePlacement to propagate your resources to the member clusters.
kubectl create ns kubecon-demo
LocalQueue
A LocalQueue is a namespaced resource that receives workloads from users within the specified namespace. This resource will point to the ClusterQueue previously created.
apiVersion: kueue.x-k8s.io/v1beta1
kind: LocalQueue
metadata:
namespace: kubecon-demo
name: lq-kubecon-demo
spec:
clusterQueue: cluster-queue
ClusterResourcePlacement
The ClusterResourcePlacement (CRP) will select the cluster-scoped resources you created (such as ResourceFlavor and ClusterQueue) and the namespace along with its associated namespace-scoped resources (like LocalQueue). The CRP will propagate these resources to all live member clusters on the Fleet.
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: sample-jobs-crp
spec:
resourceSelectors:
- group: kueue.x-k8s.io
version: v1beta1
kind: ResourceFlavor
name: default-flavor
- group: kueue.x-k8s.io
version: v1beta1
kind: ClusterQueue
name: cluster-queue
- group: ""
kind: Namespace
version: v1
name: kubecon-demo
policy:
placementType: PickAll
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 100%
maxSurge: 25%
unavailablePeriodSeconds: 60
applyStrategy:
whenToApply: IfNotDrifted
revisionHistoryLimit: 15
Job
The Job will have 400 replicas running at the same time, with its workload managed by the LocalQueue that was created earlier.
apiVersion: batch/v1
kind: Job
metadata:
namespace: kubecon-demo
name: kubecon-demo-jobs
annotations:
kueue.x-k8s.io/queue-name: lq-kubecon-demo
spec:
ttlSecondsAfterFinished: 60
parallelism: 400
completions: 400
suspend: true
manualSelector: true
selector:
matchLabels:
job-name: kubecon-demo-jobs
template:
metadata:
labels:
job-name: kubecon-demo-jobs
spec:
containers:
- name: dummy-job
image: gcr.io/k8s-staging-perf-tests/sleep:latest
args: ["2400s"]
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "1Gi"
limits:
cpu: "1"
memory: "2Gi"
ephemeral-storage: "2Gi"
restartPolicy: Never
What’s Next?
We’re excited to continue refining this strategy and roadmap based on your feedback. The shift towards multi-cluster management represents not only a technical advancement but also a more practical, reliable approach to managing large-scale Kubernetes deployments for the next generation of AI and data-intensive workloads.
We invite you to explore AKS Fleet Manager, share your experiences, and help us shape the future of scalable Kubernetes operations.