
Deploy and take Flyte with an end-to-end ML orchestration solution on AKS
Background
Data is often at the heart of application design and development - it fuels user-centric design, provides insights for feature enhancements, and represents the value of an application as a whole. In that case, shouldn’t we use data science tools and workflows that are flexible and scalable on a platform like Kubernetes, for a range of application types?
In collaboration with David Espejo and Shalabh Chaudhri from Union.ai, we’ll dive into an example using Flyte, a platform built on Kubernetes itself. Flyte can help you manage and scale out data processing and machine learning pipelines through a simple user interface.
What is a Flyte cluster, and who uses it?
A Flyte cluster provides you with an API endpoint to register, compile, and execute ML workflows on Kubernetes. It’s where the main Flyte components (user plane, data plane, and control plane) run either as a single or multiple Pods.
Adopters of Flyte include organizations running large-scale data operations and ML operations, including social media platforms, music/video streaming services, and bioinformatics companies.
With a fully configured Flyte cluster, you can:
- Process and visualize large, dynamic data sets and ensure up-to-date information retrieval
- Train ML models with versioning, enabling reproducible experimentation
- Leverage high levels of parallelism for efficient computations
- … and more!
Starting with this reference implementation, you’ll be able to take a basic Azure resource group and build an end-to-end solution on a working Flyte cluster.
This example deploys Flyte as an open-source tool on your cluster. Currently, it’s not a managed feature on Azure Kubernetes Service (AKS).
Let’s get started
Before you begin, take a look at the prerequisites on Azure, including:
- Azure subscription with at least Contributor role over all your resources using Azure RBAC.
- Azure CLI version 2.0 or later installed and configured.
- Terraform version 1.3.7 or later installed.
- Helm version 3.15.4 or later installed.
- Kubernetes command-line client, kubectl, installed and configured.
Now, you can deploy the dependencies and install Flyte following these steps and come back to this blog for a deep dive of your solution on AKS!
Which Flyte back-end components will be installed, and what do they do?
In your end-to-end solution, each of the following Flyte backend components will run on its own pod:
| Flyte component | Description |
|---|---|
| Data catalog | Service that simplifies data indexing and allows you to query data artifacts based on metadata and/or tags. Note that it’s only used when you enable caching on a Task. |
| Flyte pod webhook | Deployment that creates the Webhook Pod and is used to inject secrets into Task pods. |
| Flyte admin | Main Flyte API that processes client requests, see API specification. |
| Flyte console | Web user interface for the Flyte platform, hosted in the same Flyte cluster as Admin API. |
| Flyte propeller | Core engine that executes workflows within the Flyte data plane . |
| Flyte scheduler | Cloud-agnostic native scheduler for fixed-rate and cron-based schedules, defined at the init time for your workflow and activated/deactivated using FlyteAdmin API. |
| Sync resources | Type of agent that enables request/response services (e.g. APIs) to return outputs. |
Once you’ve applied and generated the reference Flyte Terraform, you’ll receive an endpoint to your Flyte cluster, and you can verify the following pod statuses:
kubectl get pods -n flyte
NAME READY STATUS RESTARTS AGE
datacatalog-6864645db6-99msb 1/1 Running 0 6m45s
flyte-pod-webhook-848d7db899-8wltj 1/1 Running 0 6m45s
flyteadmin-6cc67b49b4-cmt7j 1/1 Running 0 6m45s
flyteconsole-68f677797f-p4s98 1/1 Running 0 6m45s
flytepropeller-b88f7bf6d-lqc8s 1/1 Running 0 6m45s
flytescheduler-844db4658c-hfrhv 1/1 Running 0 6m45s
syncresources-767d7fc77b-5mj6n 1/1 Running 0 6m45s
Which AKS features are built into my Flyte solution?
Storage
Two Azure storage containers are created: one container stores the Terraform state and the other container stores both metadata and raw data queued up to be processed by Flyte.
Your metadata might consist of task inputs/outputs, data serialization format (protocol buffers), etc., while raw data will be unprocessed data and large objects that execution pods read from/write to the storage container.
Compute
You’ll start with a single-instance Standard_D2_v2 CPU node pool, with cluster autoscaler enabled on your AKS cluster to meet workload demands. As your workflow or application submits an increasing number of Flyte tasks, cluster autoscaler will watch for pending pods and scale up your node pool size (in this case, to a maximum of 10 nodes) to minimize downtime due to resource constraints.
To create a GPU-enabled node pool using your
aks.tfconfiguration file, update thegpu_node_pool_countandgpu_machine_typeto your desired node count and instance type, respectively, in thelocalsarray. If you specify anacceleratortype, make sure to select a supported option for flytekit.
Identity management
Workload Identity Federation with Entra ID enables fine-grained security controls to be applied. The flytepropeller, flyteadmin, and datacatalog backend components use one user-assigned MI, while the Flyte task execution pods use a separate user-assigned managed identity (MI).
Networking and security
Ingress resources are automatically configured to simplify access through a single endpoint. TLS certificates are also automated using cert-manager to secure the communication.
This reference implementation leverages open-source nginx, since Flyte uses both HTTP and gRPC to communicate the user with the control plane and to serialize workflow code, respectively.
Automatic cluster upgrades
AKS cluster auto-upgrade is enabled by default to minimize workload downtime and stay up-to-date on the latest AKS patches. The reference Flyte Terraform plan sets automatic_upgrade_channel = "stable", ensuring that the AKS cluster created will always remain in a supported version (i.e. within the N-2 rule).
Container image management
Thanks to the integration with Workload Identity Federation, Azure Container Registry (ACR) is created out-of-box with permissions for you to securely:
- Push all workflow output images to a private ACR.
- Pull your custom images through task execution pods from ACR (otherwise, a default container image is used for each Flyte workflow execution).
Monitoring
Container Insights is configured out-of-box, with system namespace logs and Flyte user workload logs ingested through Azure Monitor pipeline, to help you:
- Troubleshoot deployment issues faster through Azure Portal.
- Query historical logs using Log Analytics.
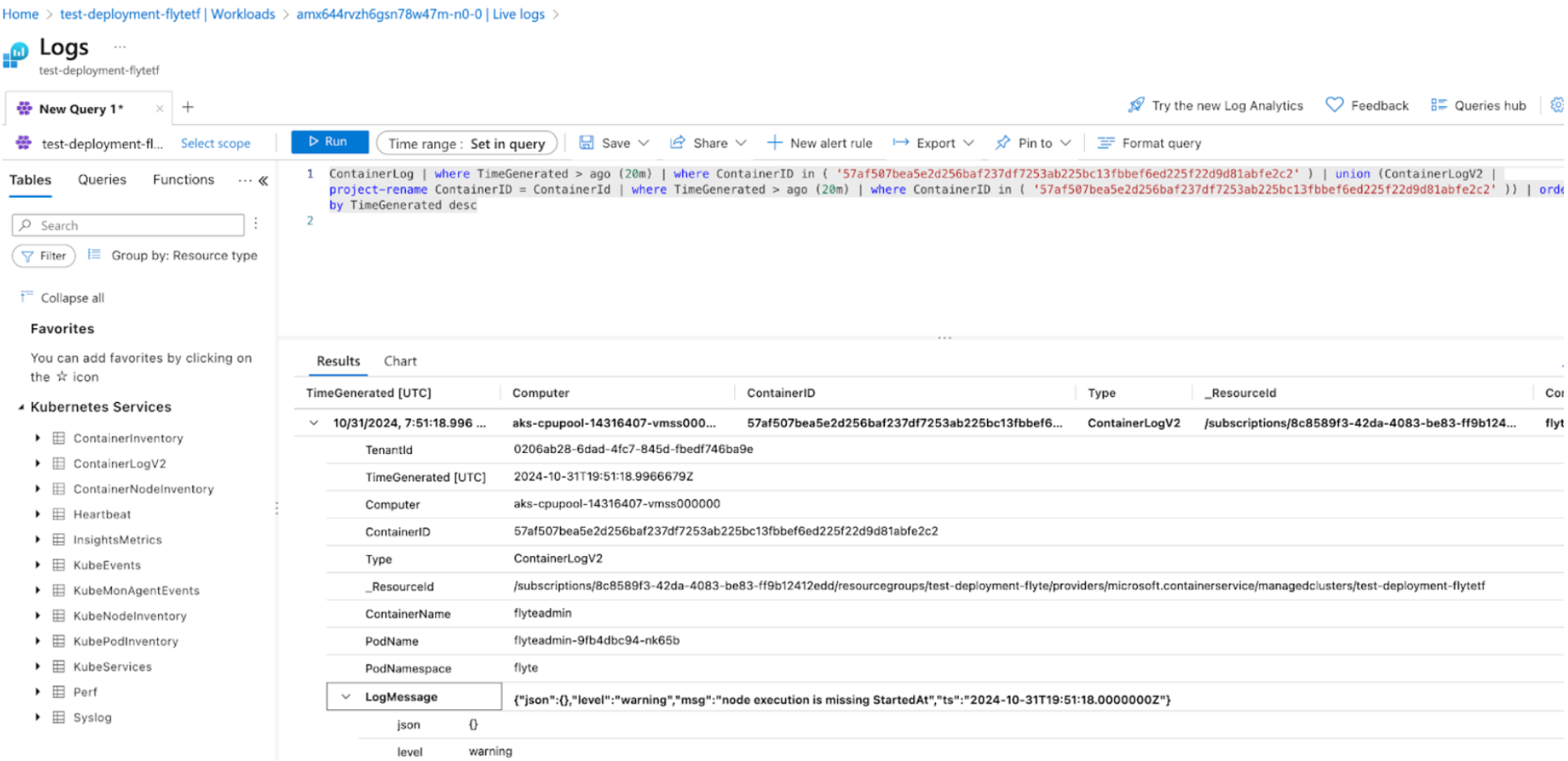
Check out my Flyte environment on AKS
Following these steps, you can update the cluster endpoint in your Flyte config, execute a sample workflow, and verify the successful execution in your Flyte console:
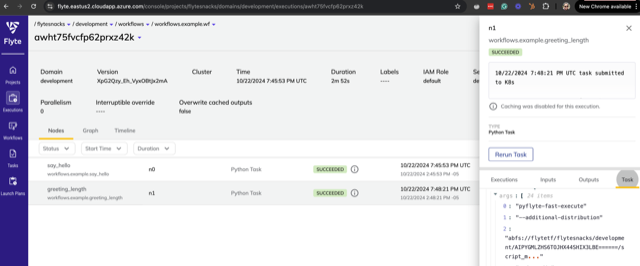
What next?
- Check out more ML and feature engineering tutorials with Flyte
- Learn about best practices for your MLOps pipelines on Azure Kubernetes Service (AKS)
- Explore the Flyte GitHub repository: https://github.com/flyteorg/flyte
- Join the #flyte-on-azure Slack channel: https://slack.flyte.org
Acknowledgements
Shoutout to Erin Schaffer for her contributions and feedback for this blog!