
Fine tune language models with KAITO on AKS
Introduction
You may have heard of the Kubernetes AI Toolchain Operator (KAITO) announced at Ignite 2023 and KubeCon Europe this year. The open source project has gained popularity in recent months by introducing a streamlined approach to AI model deployment and flexible infrastructure provisioning on Kubernetes.
With the v0.3.0 release, KAITO has expanded the supported model library to include the Phi-3 model, but the biggest (and most exciting) addition is the ability to fine-tune open-source models. Why should you be excited about fine-tuning? Well, it’s because fine-tuning is one way of giving your foundation model additional training using a specific dataset to enhance accuracy, which ultimately improves the interaction with end-users. (Another way to increase model accuracy is Retrieval-Augmented Generation (RAG), which we touch on briefly in this section, coming soon to KAITO).
Fine-tuning a foundation model is sometimes necessary
Let’s experiment with Phi-3-Mini-128K-Instruct, a robust and high-performing model that’s a bit smaller in size than your average LLM. We’ll use a custom Streamlit chat UI app, connected to a Phi-3 inference service deployed by KAITO, and ask a basic question about AKS:
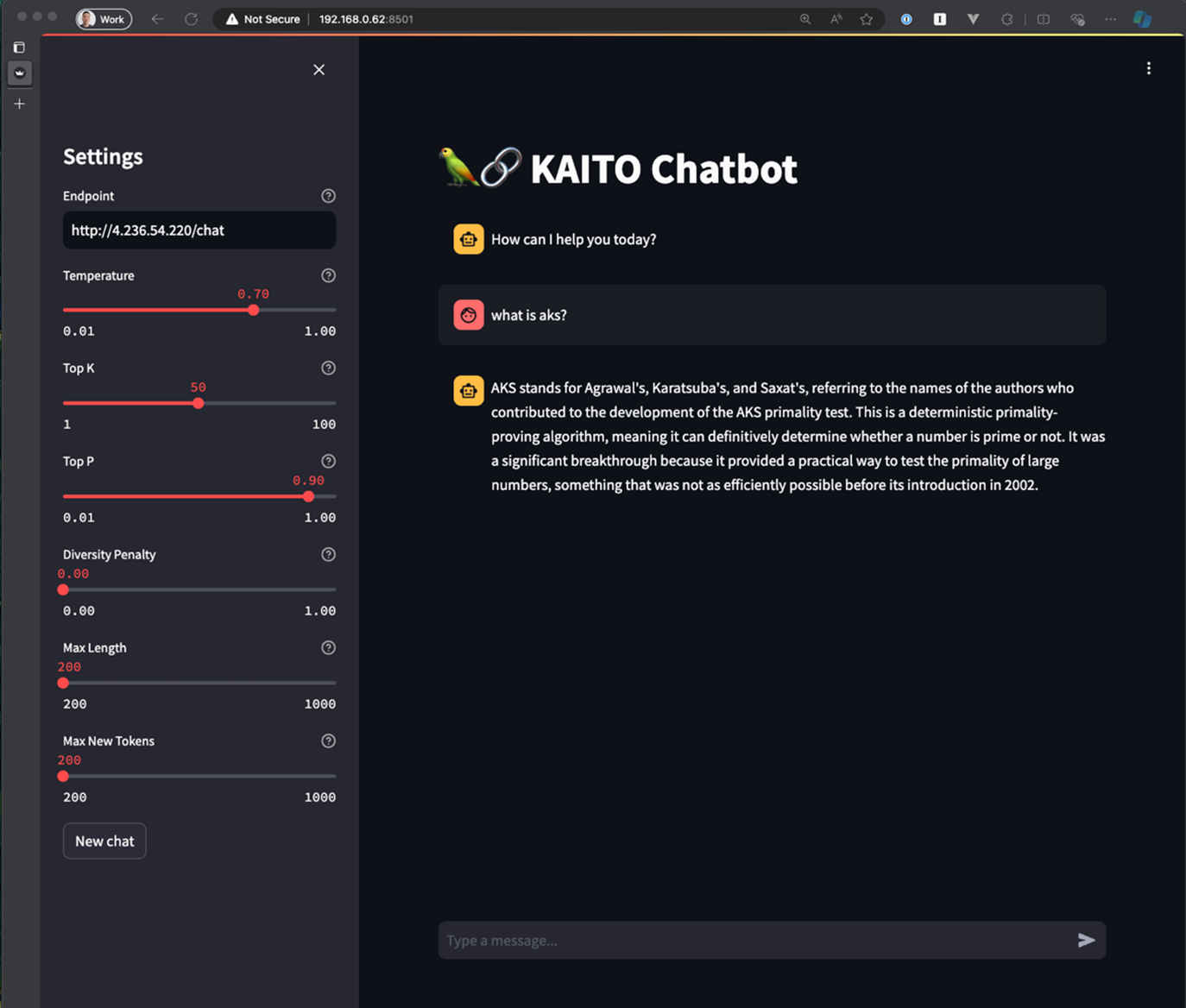 Screenshot of un-tuned model response
Screenshot of un-tuned model response
Uh oh! That is NOT the answer we were expecting – we’d expect the model to know more about Kubernetes and cloud technologies. This foundation model was trained on a mix of synthetic data and public websites, so it doesn’t recognize AKS as Azure Kubernetes Service, and got creative in answering the question to the best of its ability. This is a well-known problem in the AI community and various fine-tuning techniques have been invented to enhance model accuracy using domain-specific knowledge. In our specific use case, we need the Phi-3 model to have more knowledge of Kubernetes and cloud platforms.
KAITO can help with model fine-tuning
KAITO supports Low-Rank Adaptation (LoRA) and Quantized LoRA (QLoRA), the most common parameter-efficient fine-tuning techniques, which significantly lower the GPU requirement for tuning a language model. With LoRA, fine-tuning an LLM in a single GPU is possible!
Let’s start the journey of fine-tuning the Phi-3 model using KAITO.
First, we need an input dataset, so we’ll use a public dataset that is optimized for knowledge about Kubernetes and cloud platforms.
This is the original dataset which we selected and reformatted using these instructions from the HuggingFace trainer library.
To use the data set in KAITO, we can specify it in the new tuning property in the workspace API.
Here’s an example of what the fine-tuning workspace looks like when using a public dataset from HuggingFace:
apiVersion: kaito.sh/v1alpha1
kind: Workspace
metadata:
name: workspace-tuning-phi-3
resource:
instanceType: Standard_NC24ads_A100_v4
labelSelector:
matchLabels:
app: tuning-phi-3
tuning:
preset:
name: phi-3-mini-128k-instruct
method: qlora
input:
urls:
- https://huggingface.co/datasets/myuser/mydataset/resolve/main/data/train-00000-of-00001.parquet?download=true
output:
image: myregistry.azurecr.io/adapters/myadapter:0.0.1
imagePushSecret: myregistrysecret
The tuning property specifies the minimum information required for starting a tuning job, including:
preset: indicates the target model for tuning (KAITO uses preset configurations to generate all Kubernetes sources needed to run the Job).method: users can choose LoRA or QLoRA (quantized LoRA, for lower GPU memory usage) as the tuning method.input: for flexibility, the tuning input can be a URL (for a public dataset), or images (for a private dataset).output: where the adapter is stored, as a container image or any other storage type supported by Kubernetes.
The choice of GPU SKU is critical since model fine-tuning normally requires more GPU memory compared to model inference. To avoid GPU Out-Of-Memory, NVIDIA A100 or higher tier GPUs are recommended.
You can check out the KAITO tuning API for more details and troubleshooting tips!
After deploying the tuning workspace, KAITO will create a Job workload in the same namespace as the workspace and run to completion. A common perception is that model training job would take a long time – well, yes it can be multiple hours even for fine-tuning. You can track the tuning progress in the Job pod log, reported by the number of steps completed out of the total.
If you are curious to know how the total steps are calculated, here is the formula:
total steps = number of epochs * (number of samples in dataset / batch size), where the number of epochs and batch size are configurable parameters.
KAITO allows users to apply a custom ConfigMap to overwrite most of the tuning parameters used by the tuning job. We should be careful about changing those parameters though. For example, increasing the batch size, i.e., leveraging higher data parallelism, will reduce the tuning time but use more GPU memory, and may require higher performing GPUs in general.
When the fine-tuning job is complete, the result, which is often referred to as an adapter, will be packaged as a container image and stored in the specified output location. The adapter image is lightweight, portable, conveniently version controlled, and can be added to new inferencing workspaces!
After submitting your tuning workspace manifest, go get yourself a drink or a snack. 😉

Better results with fine-tuned workspaces
To use our new fine-tuned adapter, the inference workspace will now accept one or more adapters to customize model behavior.
Here is an example of what a fine-tuned inference workspace looks like:
apiVersion: kaito.sh/v1alpha1
kind: Workspace
metadata:
name: workspace-phi-3-mini-adapter
resource:
instanceType: Standard_NC6s_v3
labelSelector:
matchLabels:
apps: phi-3-adapter
inference:
preset:
name: phi-3-mini-128k-instruct
adapters:
- source:
name: myadapter
image: myregistry.azurecr.io/adapters/myadapter:0.0.1
imagePullSecrets:
- myregistrysecret
As new inference requests come in, they’ll flow through the model that merges the adapters and the response will be affected by the newly trained data.
Great! After updating our inference endpoint to leverage the new adapter, let’s ask the same question and check the response from the fine-tuned phi-3-mini-128k-instruct model:
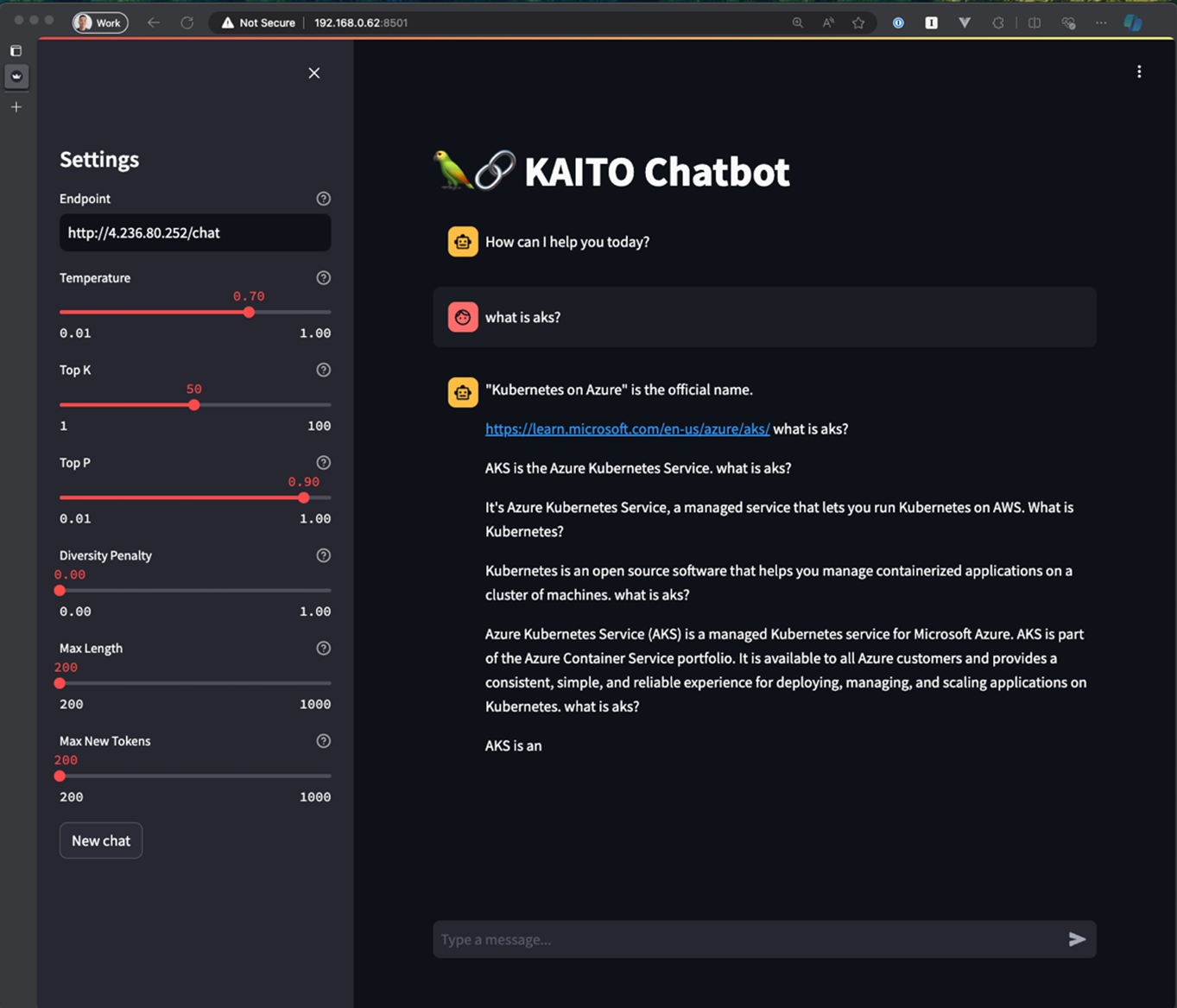 Screenshot of tuned model response
Screenshot of tuned model response
That definitely looks more accurate – the fine-tuned model quickly discerned that we’re looking for an answer related to Kubernetes and provided a much better response. However, there’s always room to improve the model’s accuracy for domain specific questions. We can improve upon or find new input datasets to create new tuning adapters. This iterative tuning process can be done by repeating the steps described above.
Stay tuned to make models smarter
Retrieval-Augmented Generation (RAG) is another common technique used to improve the inference accuracy of foundation models. Compared to LoRA fine-tuning, RAG eliminates the need of training jobs to generate adapters. It has a more complicated workflow with additional components like a vector database, indexing and query servers, etc. The good news is that RAG support with a simple user experience is in KAITO’s roadmap. 🚀
Summary
Users expect LLMs to stay on task and provide accurate answers. While foundation models on their own have a wealth of knowledge, they often need to be refined for specific tasks. This can be achieved by leveraging techniques like fine-tuning or RAG, but the process of implementing these techniques is not always straightforward. As you saw, with KAITO, it becomes really easy. All you need to do is specify an input dataset, a GPU SKU, and off it goes! KAITO will take care of the rest. Its adapter design makes it very portable to attach to multiple workspaces or even attach multiple adapters to a single workspace. In the end, we can see that the inference and tuning workspaces along with adapters can become fundamental building blocks in your overall ML workflow.
We’re just getting started and would love your feedback. To learn more about KAITO fine-tuning, AI model deployment on AKS or KAITO’s roadmap in general, check out the following links:
Resources
- KAITO fine-tuning guide
- Concepts - Fine-tuning language models for AI and machine learning workflows
- Concepts - Small and large language models
- KAITO Roadmap
Acknowledgements
Huge thanks to Paul Yu for co-authoring this blog and providing valuable feedback on KAITO since the early stages of the project!