Welcome to Day 1️⃣ of Azure AI week on ##60Days Of IA
In today's post, we'll introduce you to the Contoso Chat sample - a comprehensive end-to-end reference sample that walks you through the journey of building the customer support AI application we talked about in our kickoff post yesterday. By the end of this tutorial, you will be able to:
- explain how to build a copilot app end-to-end on Azure AI
- explain what Retrieval Augmented Generation does for copilot apps
- explain what prompt flow is and how it streamlines your workflow
- describe the Azure AI platform and Azure AI SDK capabilities
Ready? Let's go!
What You'll Learn Today
- Contoso Chat Sample: Building a copilot with Azure AI and Prompt flow
- Retrieval Augmented Generation: Design pattern for using custom data
- Prompt flow: Open-source tooling for orchestrating end-to-end workflow
- Azure resources: Provisioning Azure for the Contoso Chat AI project
- Hands-on lab: Step-by-step tutorial to build & deploy Contoso Chat
- Exercise: Fork the sample then work through the hands-on tutorial.
- Resources: Explore this collection for samples, docs and training resources.

Contoso Chat Sample
The Contoso Chat sample provides a comprehensive end-to-end reference example for using Azure AI Studio and Prompt flow, to build a copilot application end-to-end. The sample implements a customer support chat AI experience - allowing customers on the Contoso Outdoors website to ask questions about related products and receive relevant responses based on their query and purchase history. The illustrated guide below gives you a high-level overview of the steps involved in building the application - from provisioning Azure resources to deploying and using the chat AI endpoint. To learn more about the application scenario, refer to our kickoff post for this week.

RAG Design Pattern
Our first step is to define the application architecture for Contoso Chat. We know we want to have our copilot grounded in our data so that customer queries return responses that reflect the product catalog or customer purchase history.
The challenge is that Large Language Models (LLM) are trained on massive datasets so the default responses may not be relevant or accurate with respect to your data. This is where prompt engineering and design patterns like Retrieval Augmented Generation (RAG) come in. RAG is a design pattern that uses an information retrieval component to get data relevant to the user prompt, then augments the prompt with that context before sending it to the LLM, as illustrated below.
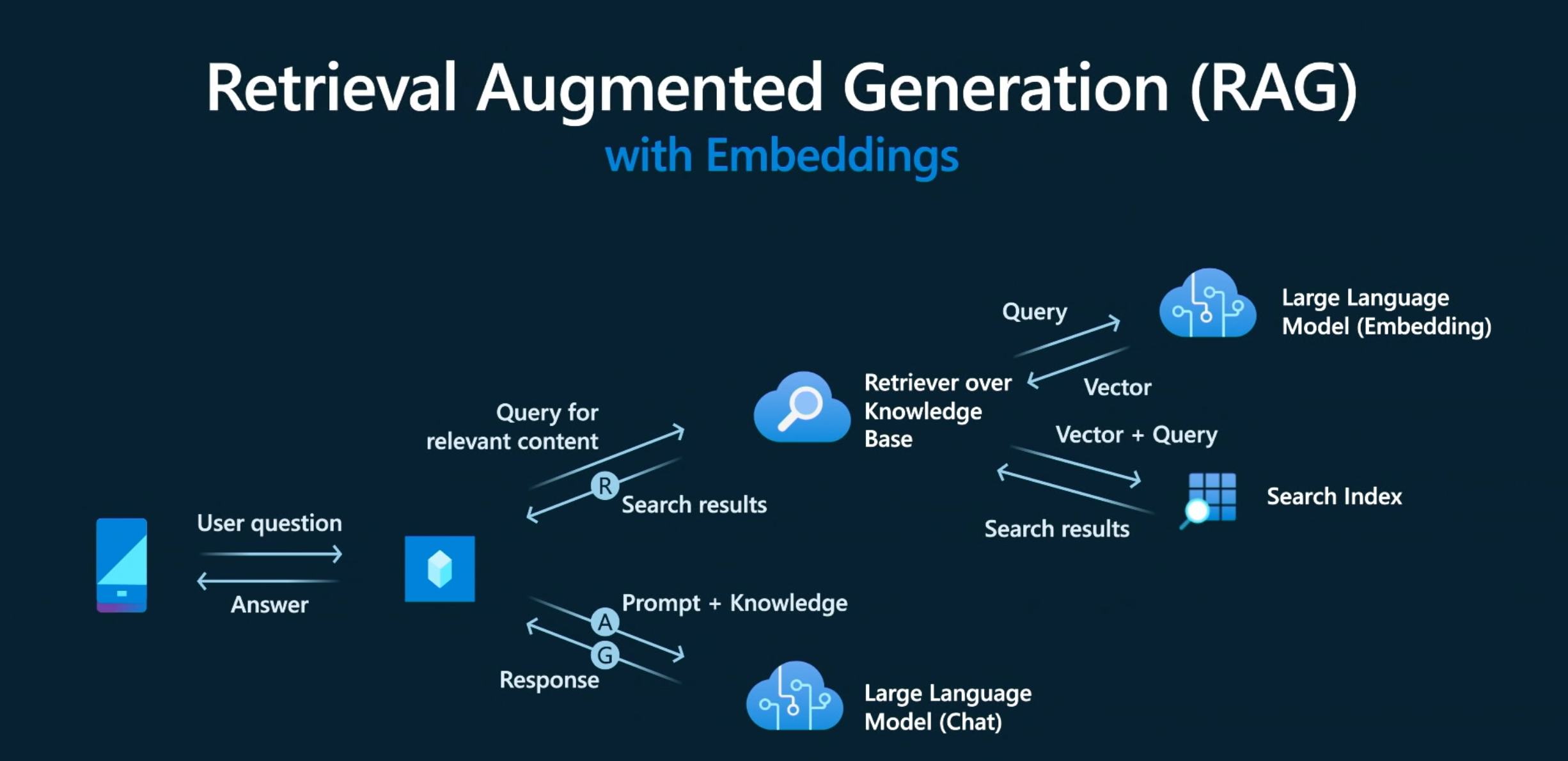
We can break down the workflow into the following steps:
- User asks a question ("User prompt")
- The question is sent to an information retrieval component ("AI Search")
- This vectorizes the query ("Embedding Model")
- And uses the vector to retrieve relevant results ("Product Index")
- Results are used to augment User prompt ("Model prompt")
- The enhanced prompt is sent to the LLM ("Chat completion")
The answer is then returned to the user, who now sees a response that is more relevant to the products in your catalog, and personalized to their purchase history. Note that this basic copilot workflow requires us to deploy two large language models:
- Text-Embedding model (e.g.,
text-embedding-ada-002) that vectories the user query - Text-Generation model (e.g.,
gpt-35-turbo) that generates the final response
Prompt flow Orchestration
Implementing the RAG pattern requires a number of interactions between the language model deployments and the data sources used (e.g., search index for products, cusomer database for purchase history), and coordination of intermediate steps before the final response can be delivered. This is where frameworks like Prompt flow, LangChain and Semantic kernel come in.
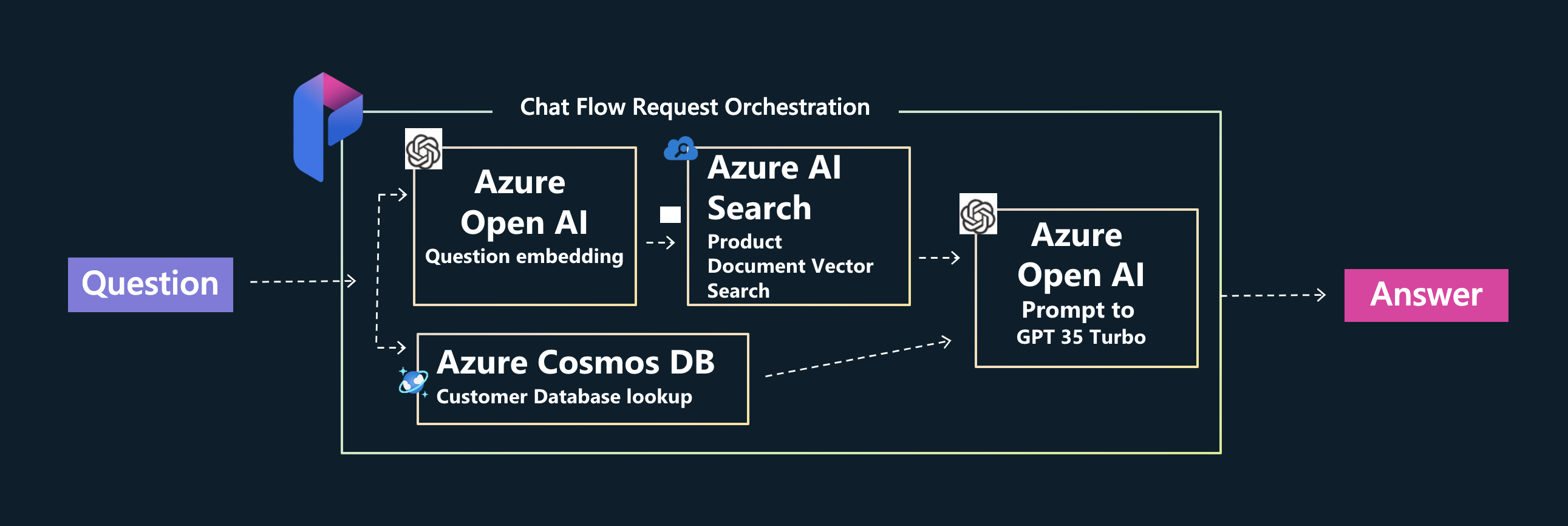
The Contoso Chat sample makes extensive use of Prompt flow - an open-source project on GitHub, with its own SDK and VS Code extension. Prompt flow provides a comprehensive solution that simplifies the process of prototyping, experimenting, iterating, and deploying your AI applications. It is recommended for use as a feature within Azure AI Studio, making it a natural first choice for building our Contoso Chat application. The figure shows a high-level architecture diagram showcasing the Azure components used with Prompt flow as the orchestration layer.
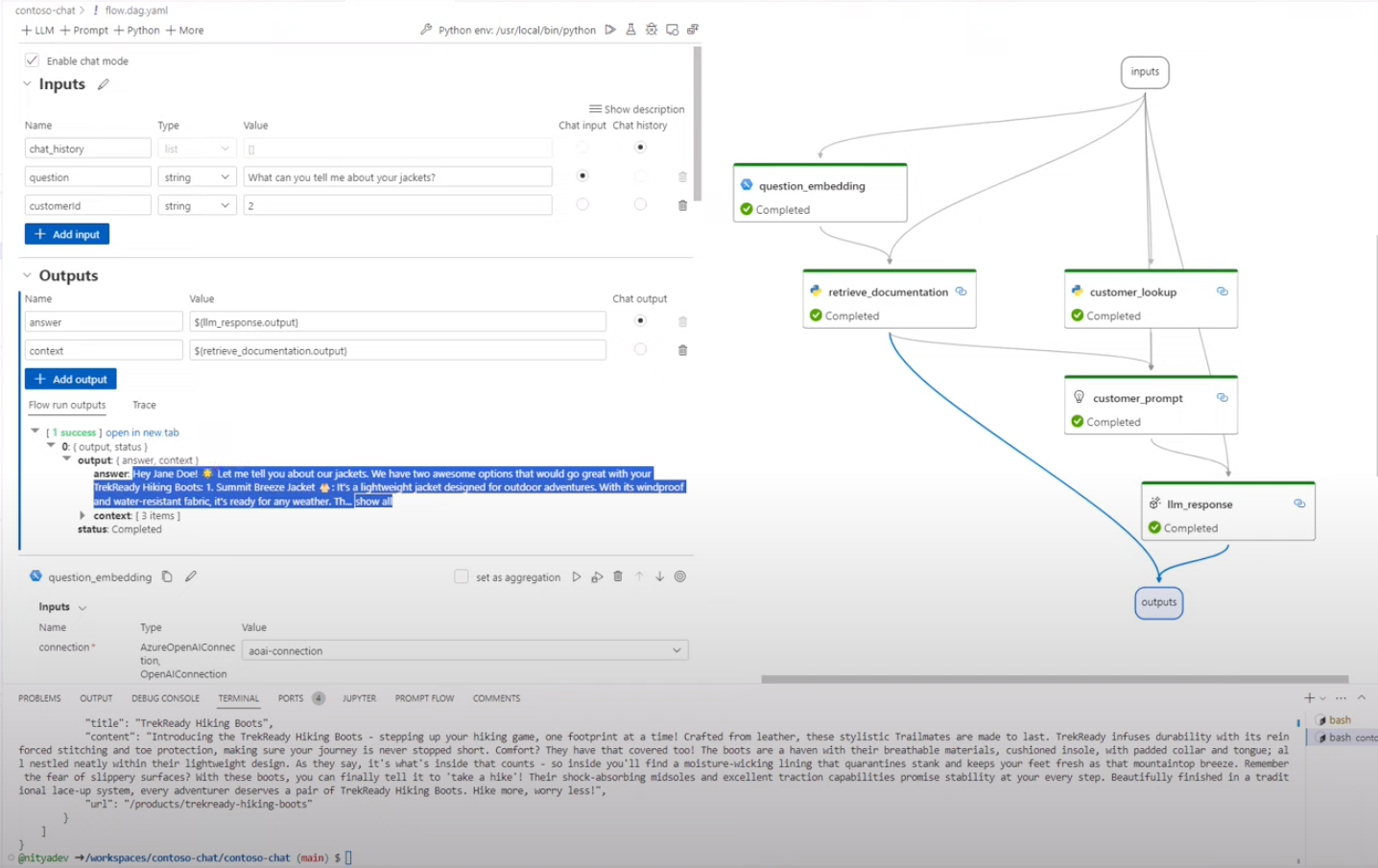
With Prompt flow, your application is defined as a a directed acyclic graph of nodes (flow.dag.yaml) that connect input (prompt) and final output (response) - with intermediate nodes implemented as Python functions (tools) that process or transform the data flowing through them. The Prompt flow extension in VS Code provides a rich visual editor capability as shown below, making it easy to define, debug, run, and test, your application in a local development environment. This view also helps us see how the RAG pattern is implemented in practice, in our copilot.
Azure Provisioning
The Contoso Chat sample comes with a provision.sh script that will pre-provision many of the Azure resources for you, for use in the development workflow. To get started with the implementation, follow the instructions in the README file in the repo by doing the following:
- Fork the sample to your own GitHub account
- Setup development environment using GitHub Codespaces
- Authenticate with your Azure subscription
- Run the Provisioning script and verify your setup is complete
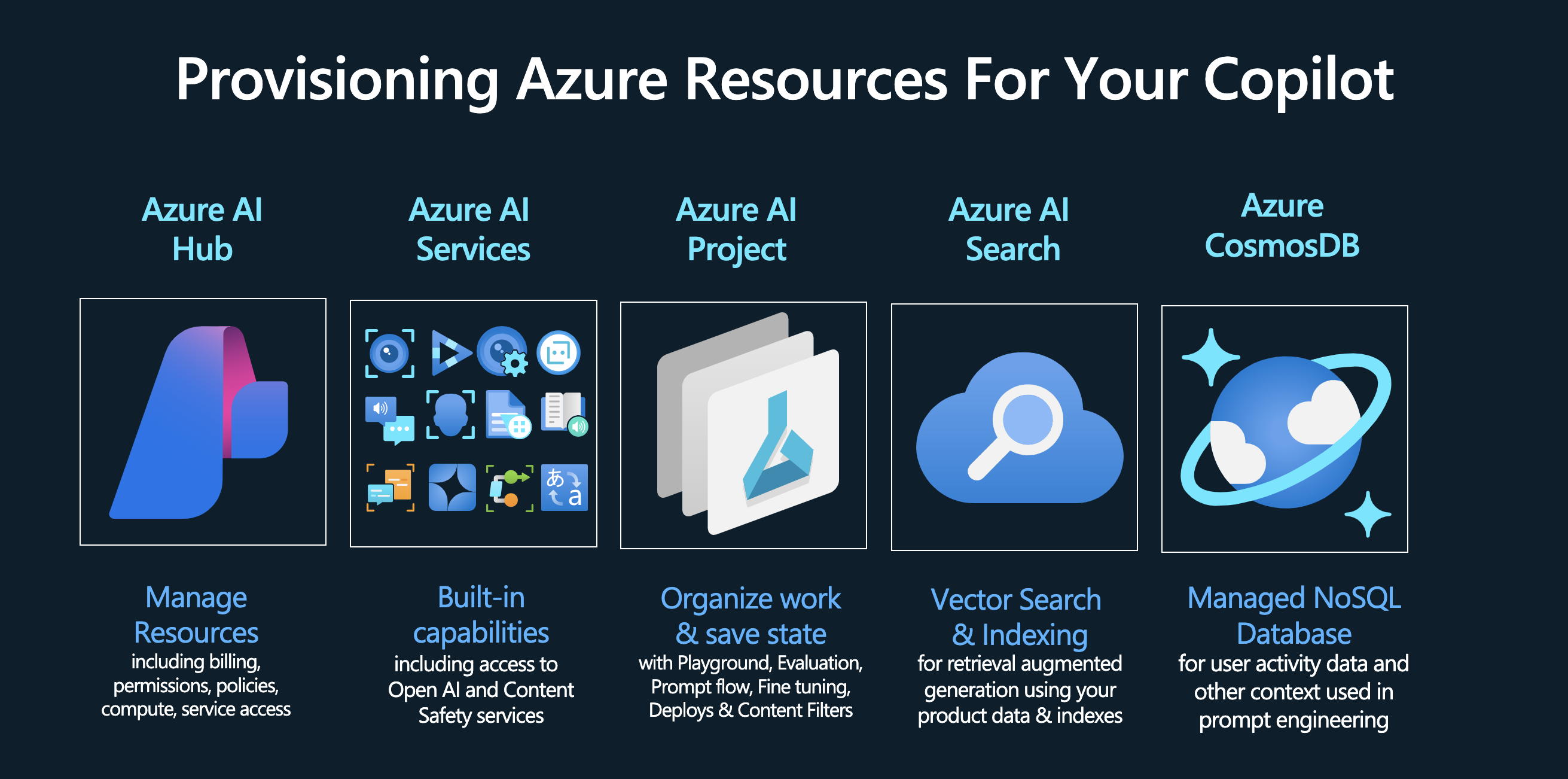
At this point, you should have an Azure resource group created for your project with the following resources created for your application. Note that in order to complete this step, you must have a valid Azure subscription that has been given access to the relevant Azure OpenAI services. You must also have available quota for model deployments in the specific regions that we use in the provisioning script.
Hands-on Lab
You can now complete the step-by-step tutorial in the README to build, evaluate and deploy the application. Let's quickly review the main steps involved in the end-to-end workflow.
| Stage | Description |
|---|---|
| 1. Build a Copilot. | Get familiar with the application codebase. Check out the data/ folder to see the data we will be using for customer order (history) and product catalog (index). |
| 2. Provision Azure. | Run the ./provision.sh script or manually provision the required resources. This should setup an Azure AI hub (manage), an Azure AI project (build), an Azure Cosmos DB resource (customer data) and an Azure AI Search resource (product index). Verify you have a config.json created (for local Azure configuration) and an .env file (for relevant keys and endpoints for access). |
| 3. Add Models & Data. | The provisioning script does the model deployments - but review them now. Make sure you have a chat completion model (gpt-35-turbo), a chat evaluation model (gpt-4) and a text-embeddings model (text-embedding-ada-02). Use the provided notebooks to populate the data in Azure Cosmos DB and Azure AI Search. |
| 4. Add Connections | The devcontainer configuration ensures you have the Prompt flow extension installed in VS Code, and the pf too for command-line, by default. Use the provided notebooks to setup connection configurations from prompt flow to key services (Azure OpenAI, Azure AI Search, Azure Cosmos DB) for use in related notes of the prompt flow graph. Use the pf tool to validate these were setup correctly (on VS Code). The provision script may have setup some of these for you in the cloud (Azure) for use in later stages (deploy) - take a minute to verify and correct these as described in README. |
| 5. Build Prompt Flow | You are all set to run the prompt flow with your data in Azure. Explore the components of the prompt flow. Click the stylized P icon in the sidebar to see the Prompt Flow extension activity menu. Open the contoso-chat/flow.dag.yaml file in VS Code, then click the Visual Editor option to see the view shown in the earlier screeshot above. Run it to validate it works - then explore the nodes, outputs and code. |
| 6. Evaluate Prompt Flow | You can complete a local evaluation by opening the relevant notebook and running it cell-by-cell. Review the code in each cell of the notebook, then analyze the output to understand what the relevant metrics are telling you about the quality of the basic flow. The batch run step takes a while and requires Azure connection setup so consider that an optional step. Switch periodically to the Azure AI Studio website view to see how the relevant Azure AI project pages are updated to show the status of various activities or configurations. |
| 7. Deploy Prompt Flow | Deploying the prompt flow is a 2-step process. First, we need to upload the flow (code, assets) to Azure AI Studio. Do this using the provided notebook, or you can try to do this manually using the import option in Azure AI Studio under the Prompt Flow section. Once uploaded, you need to select a runtime ("automatic") and start it to get a compute instance provisioned to execute your flow. Use that to test that your flow was imported successfully. Then click the Deploy option to deploy the flow. This will take a while - refresh the Deployments page to get updates. Once deployment is successful, use the built-in testing feature to try a simple question against the hosted API endpoint. Congratulations Your chat AI endpoint is ready for use! |
| 8. Summary & Clean up | This was a lot. Note that almost every step of this process can be achieved using code (SDK), command-line (CLI) or UI (Studio website) so explore the documentation. Note that Azure AI Studio is in preview so the features are constantly evolving and things may break unexpectedly - send feedback if so! Finally, don't forget to delete your codespaces and your Azure resources for this lab to avoid unnecessary charges. And watch the sample repo for updates on workshop content and exercises to extend this further. |
Completing this workshop can take 60-90 minutes based on your level of familiarity with the tools. In the next blog post, we'll dive a bit deeper into the process with specific focus on the Azure AI SDK to understand how you can implement core steps of the workflow from your Python application. And, in the final post of this week, we'll return to the Contoso Chat sample to explore deployment and evaluation in more detail - with additional guidance for ensuring responsible AI usage in your generative AI applications.
Exercise
Congratulations! You made it to the end of this whirlwind tour of the Contoso Chat sample. Now it's time for you to do the hard work of building this yoursel!! Start by forking the sample - then follow the step-by-step instructions in the README.
Resources
We've referenced a number of links and samples in this post. Bookmark the Azure AI Studio: Code-First Collection and revisit it regularly for an updated list of resources for code-first development of generative AI applications on Azure.