05 - Add knowledge to your agentic workflow using AI Search integrated vectorization
This module explains how to use advanced techniques to add custom knowledge to your Azure Logic Apps agents using RAG ingestion and retrieval. This module builds from module 4's agent implementation to create a simpler retrieval workflow using a search index with an integrated vectorizer.
When finished with this module, you'll have gained the following knowledge:
- Azure AI Search integrated vectorization: How to use Azure AI Search's integrated vectorization for RAG retrieval workflows, simplifying the workflow design.
Part 1 - Data ingestion and Indexing
notePrerequisites for this module are the following
- You have access to an Azure Storage Account resource. For steps on setting this resource up, follow the guide here Create an Azure storage account.
- You have a upload a pdf document to your storage resource. The link to this resource will be used in the next steps. The pdf used in this module can be download here Benefit_Options.pdf
- You have access to an Open AI Service and this service has a deployed model for generating text embeddings. For more on creating this service visit Explore Azure OpenAI in Azure AI Foundry.
- You have access to an Azure AI Search service. For more on creating this resource visit here Create an Azure AI Search service.
Part 1 - Create your AI Search resources
Using the supplied index JSON file we will create your index in Azure AI Search. More on integrated vectorization here. This index will have integrated vectorization enable so that sending embeddings to your index will not be necessary. Next, we will build a data ingestion pipeline in Azure AI Search to ingest your document directly into your index.
Step 1 - Create your index
- In the Azure portal, create or open your Azure AI Search resource.
- On the top menu select (+ Add index), then select Add index (JSON)

- Copy the context of the file: index_schema and paste it into the dialog box. The JSON contects contains placeholders for your OpenAI resource values for the following: {OpenAI resource URI}, {deployment ID}, {API key}, and {model name}. Follow below steps to find these values in your OpenAI resource.
- In a new browser tab on the Azure portal, create or open your Azure OpenAI resource.
- On the Overview tab, click the Click here to view endpoints link.
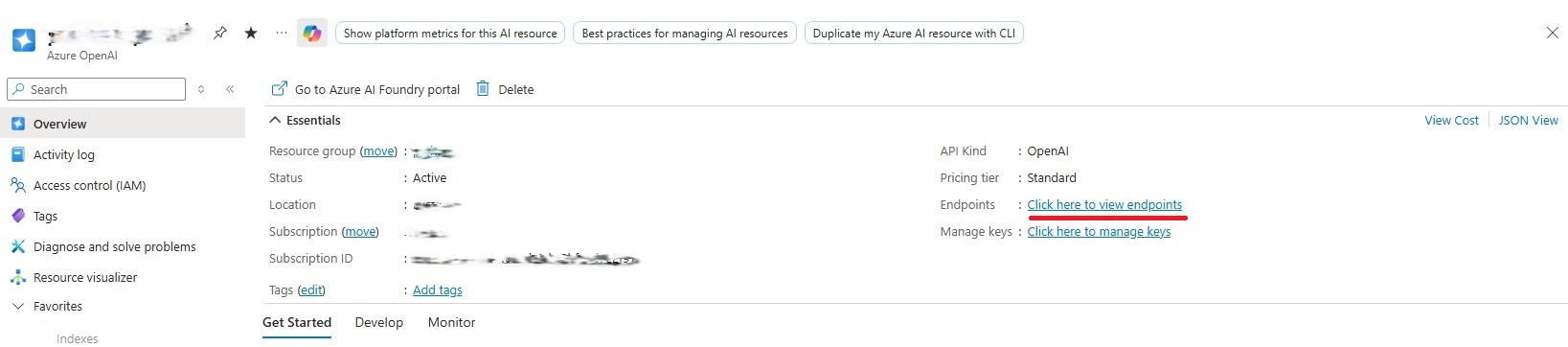
- Replace {OpenAI resource URI} in the JSON with the value from the Endpoint.
- Replace {API key} in the JSON with the value from KEY 1.
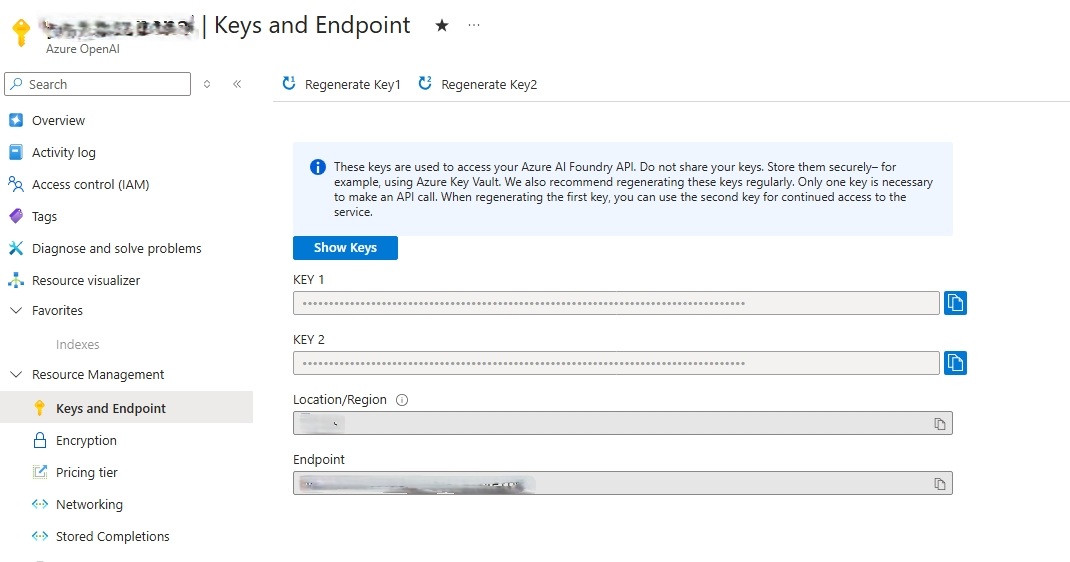
- Go back to the Overview tab.
- Click the Explore Azure AI Foundry portal button.
- Click Continue on the next page.
- From the Azure Foundry page, click Deployments on the left side menu.
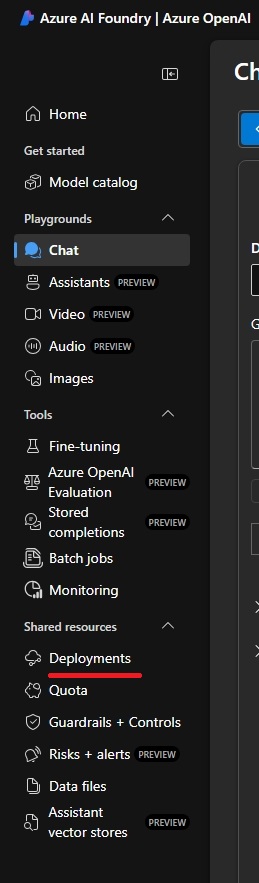
- From the Model deployments screen find your text embedding deployments.
- Replace {model name} in the JSON with the Model name of your deployment. *text-embedding-ada-002 from our example.
- Replace {deployment ID} with the name of your deployment. text-embedding from our example.
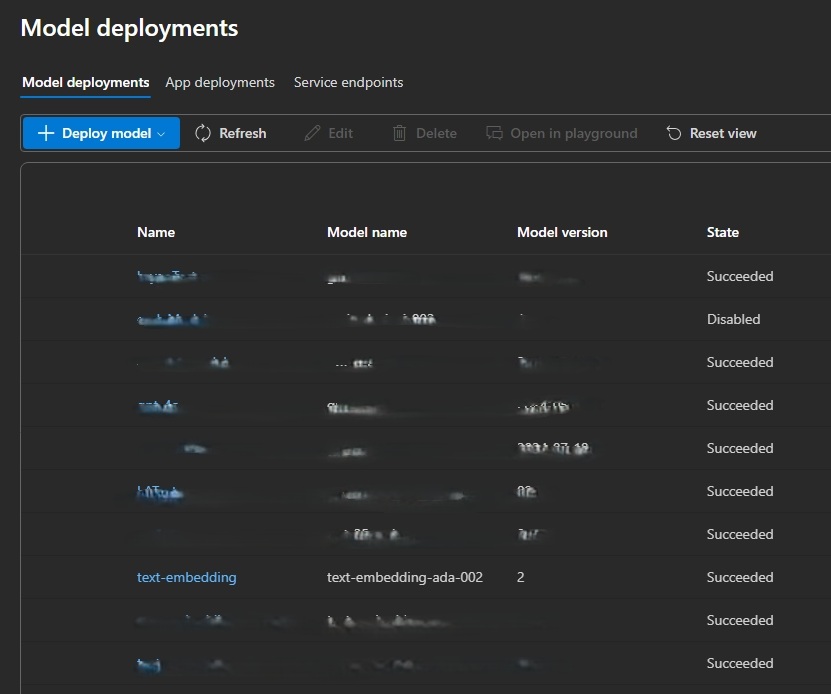
- If you do not have an embedding model deploy, follow the steps here to deploy a model.
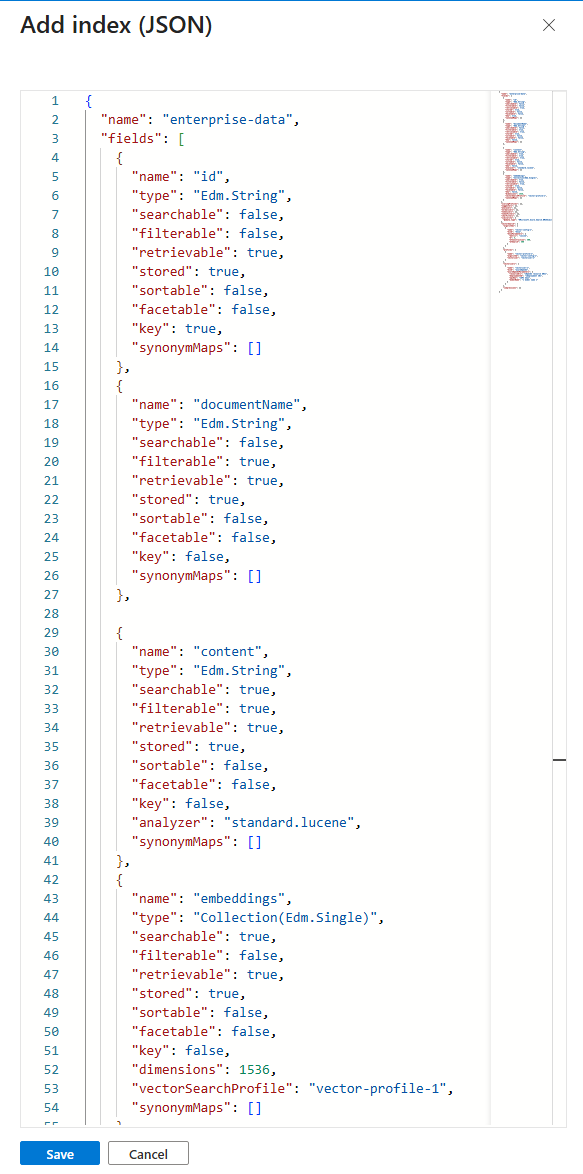 1.With the values replaced for your OpenAI resource, click Save.
1.With the values replaced for your OpenAI resource, click Save.
- After successfully saving the index, click on the Indexes left side menu item.
- Verify the index you created is listed.
Step 2 - Create your data ingestion pipeline
Part A - Create your data source
- From your AI Search index resource, click the Data sources left side menu item.
- Click the **(+ Add data source) button from the top menu, then click Add data source.
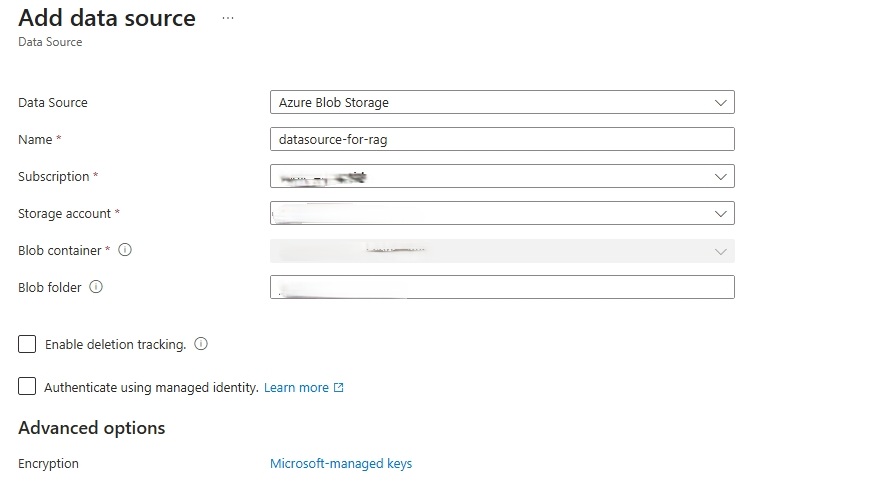
- On the Add data source page. Fill the form to point to your Azure Blob Storage where your document is located.
- Set Data Source to Azure Blob Storage.
- Set Name to a name you can remember to reference this data source.
- Set Subscription, Storage account, Blob container, and Blob folder (if necessary) to point to your Blob storage account where your file to ge ingested is stored.
Part B - Create your Skillset
- From your AI Search index resource, click the Skillsets left side menu item.
- Click the + Add skillset button.
- This will take you to a default skillset JSON page.
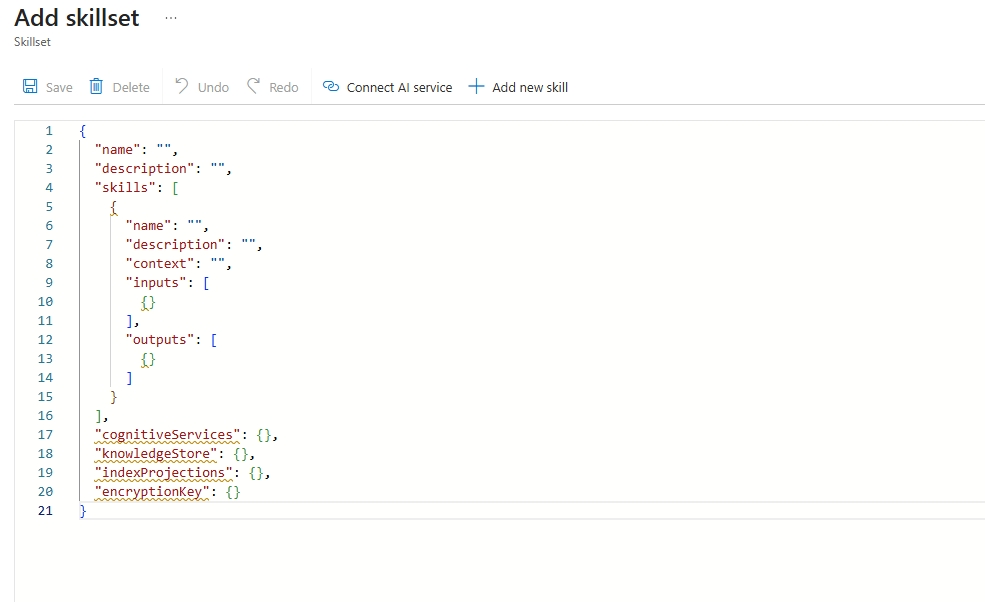
- Copy the cotents of the skillset JSON here. This file defines two "skills" that will execute when your document is ingested.
- The split-documents skill will chunk your document into section that are small enough to be sent to OpenAI for generating embeddings,
- The create-embeddings skill will send your text chunks to your OpenAI text embeddings deployment and return their embeddings.
- Replace the value resourceUri with your OpenAI resource endpoint.
- Replace the value apiKey with your OpenAI resource's api key.
- Click Save.
Part C - Create your indexer
- From your AI Search index resource, click the Indexers left side menu item.
- Click (+ Add indexer) at the top menu, then click Add indexer.
- Set the Name property.
- Select the integrated vectorizer index you created on the Index selector.
- Set the Datasource to the data source created in Part A above.
- Set the Skillset to the skillset created in Part B above.
- Set the Schedule to the value that makes sense you you. For our example we will set the value to Once meaning the indexer will run once after saving.
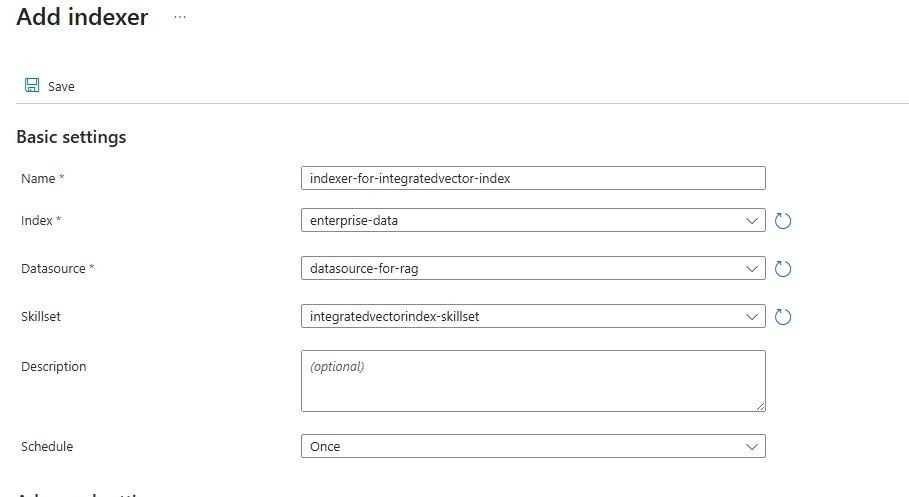
- Click Save.
- Verify the indexer has run successfully
Part 2 - Create your knowledge agent
To simplify the retrieval workflow compared to module 4, you will use the Azure AI Search natural language action in your workflow. This action will automatically engage the integrated vectorizer for generating embeddings. Because the search service creates embeddings for the incoming user queries, your Logic App will not need a separate action to generate embeddings.
Benefits
- Fewer actions in your Logic App (simpler workflows)
- Reduced API calls and maintenance
- Consistent vectorization when the same model is used for indexing and querying
Step 1 - Create your retrieval workflow
-
In the Azure portal, open your Standard logic app resource.
-
Find and open your conversational agent workflow in the designer.
On the designer, select the agent action. Rename the agent: Document knowledge agent. Next enter the System Instructions
You are a helpful assistant, answering questions about specific documents. When a question is asked, follow these steps in order:
Use this tool to do a vector search of the user's question, the output of the vector search tool will have the related information to answer the question. Use the "content" field to generate an answer. Use only information to answer the user's question. No other data or information should be used to answer the question.
- On the designer, inside the agent, select the plus sign (+) under Add tool.
- Click on the Tool, and rename it to Document search tool. Then add the follow Description Searches an azure search index for content related to the input question.
- Click the plus (+) sign to add a new action.
- Search for Azure AI Search (built-in).
- Select the Search vectors with natural language action.
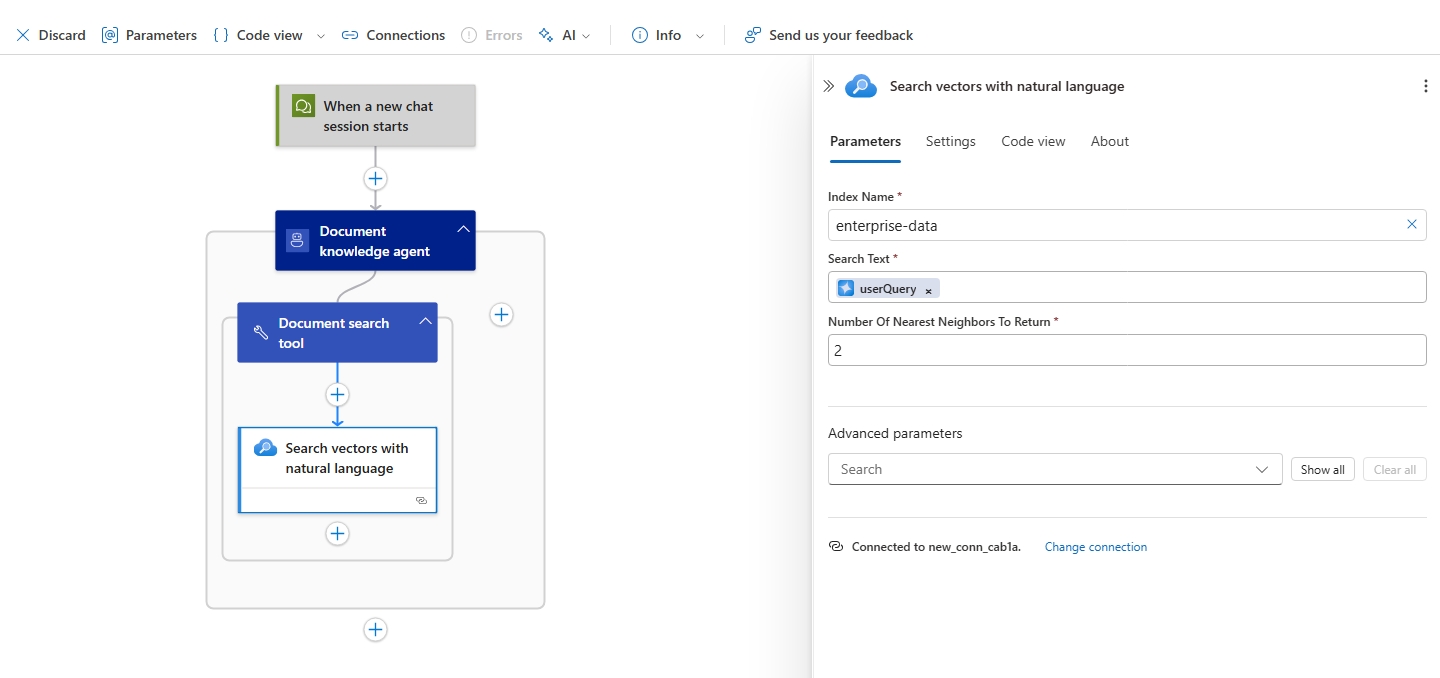
- Set Index Name to the name of your index.
- Set Search Text to the agent parameter previous created named userQuery.
- Click Save on the Designer's top menu.
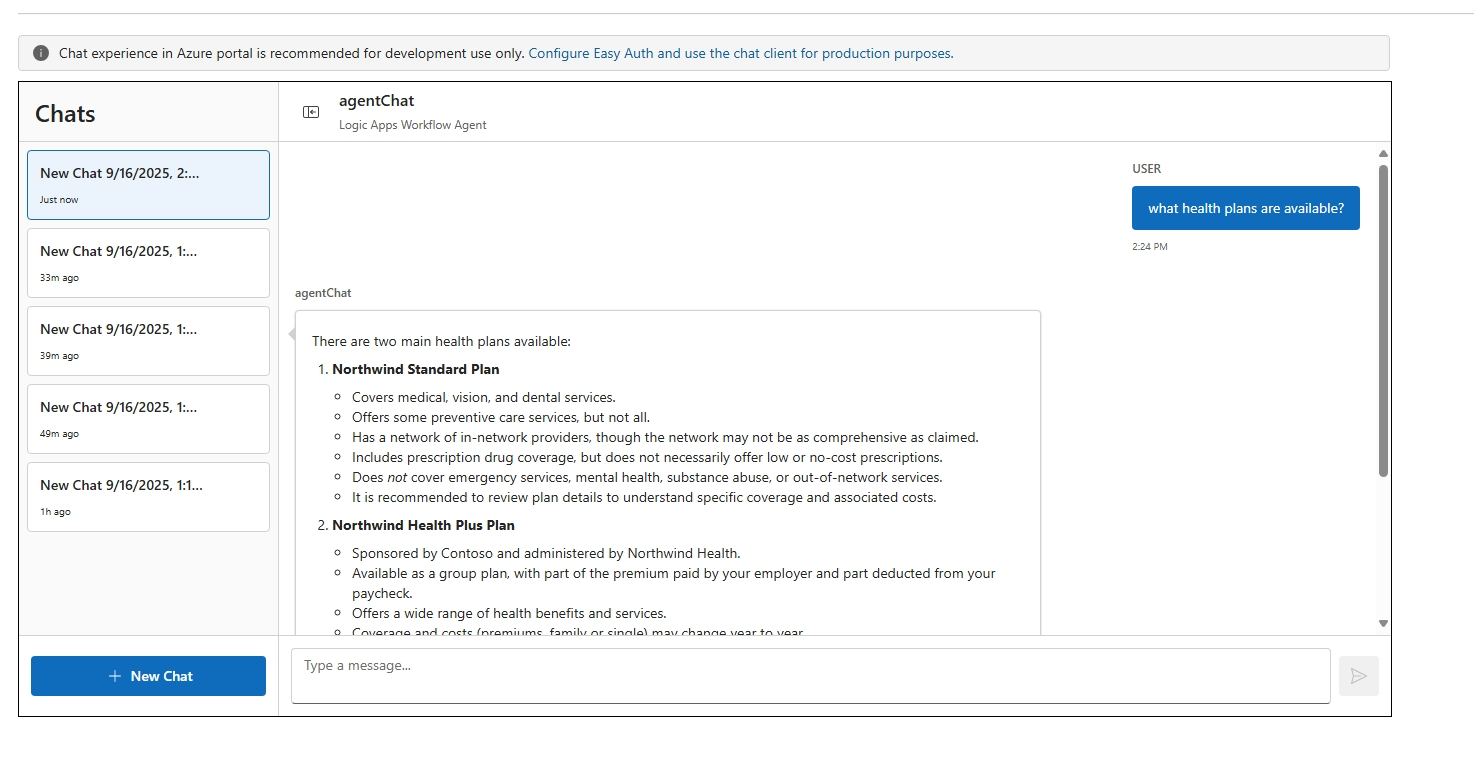
- Test your workflow
- Click on Chat from the left side menu.
- Submit the question What health plans are available?.
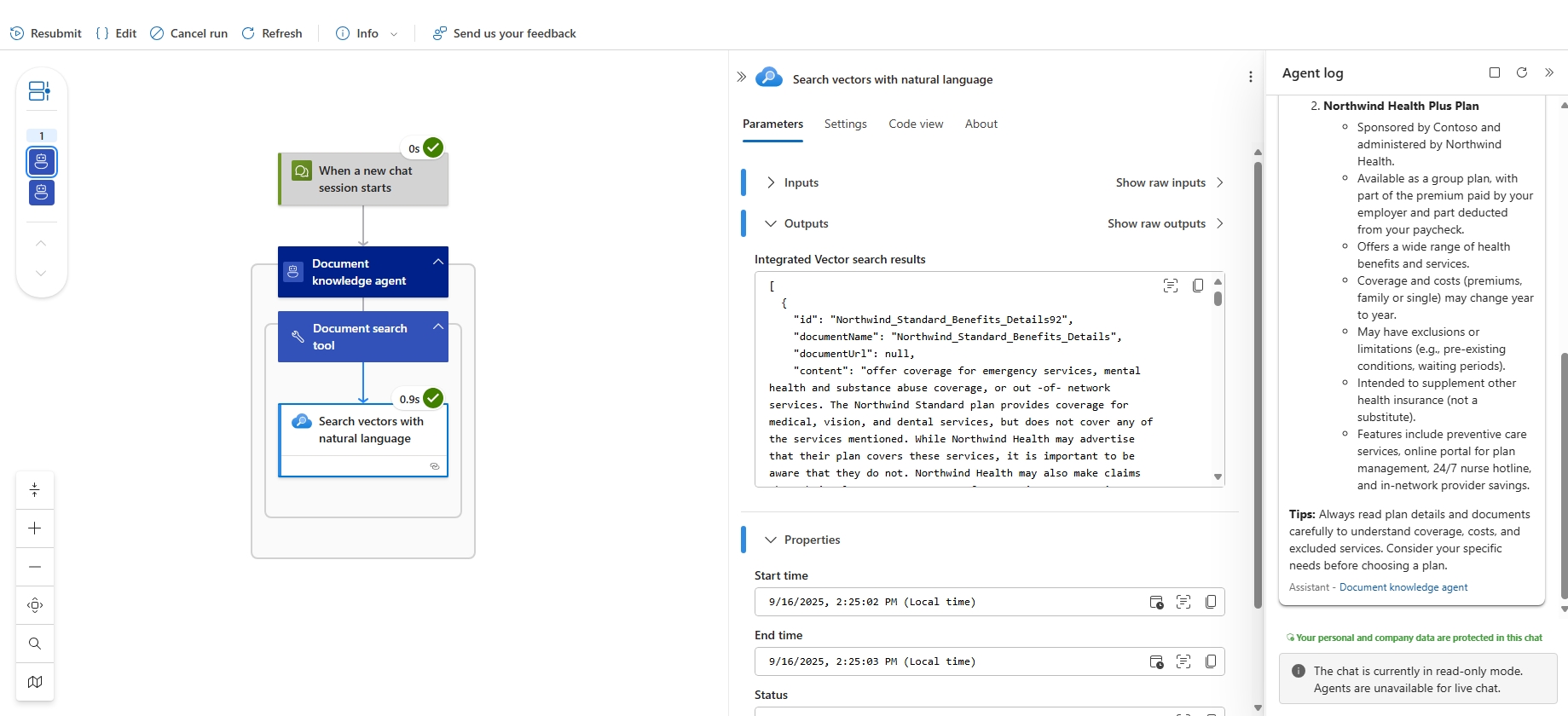
- Verify workflow execution
- Click on Run history from the left side menu.
- Click on the latest run and verify the agents execution.
Notes and considerations
- Use the same embedding model/deployment for both indexing and query vectorization to ensure compatible vectors.
- Verify quota, permissions, and cost implications for the configured embedding deployment.
- Keep monitoring and adjust the number of nearest neighbors and scoring parameters to tune relevance.