Evolve-Instruct
Overview
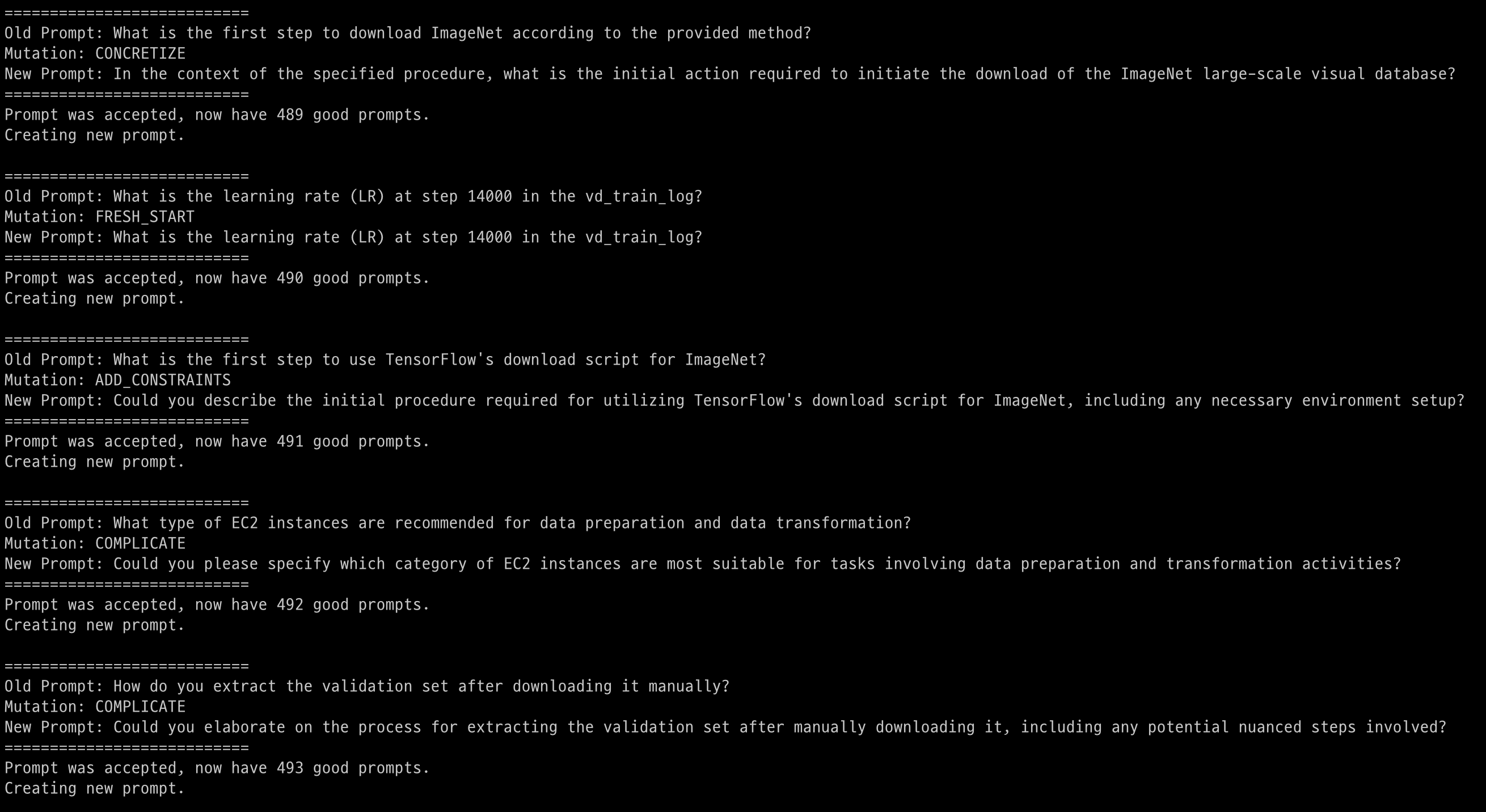
The Evolve Instruct method creates more diverse and complex instructions by modifying (augmenting) existing instruction data. To achieve this, this technique utilizes LLMs such as GPT-4o to rewrite or transform existing instructions. In particular, It uses two strategies to make instructions more complex or create new instructions: In-depth Evolving and In-breadth Evolving.
- In-depth Evolving: Make an instruction more difficult by adding constraints to it, making it more specific, increasing the logical reasoning steps, or complicating the input.
- In-breadth Evolving: Create completely new commands based on existing commands to expand the scope of topics and technologies and increase the diversity of your datasets.
Implementation
This open-source implementation is based on the WizardLM paper and h2o-wizardlm. We added the following features to the original implementation:
- Modified it to be able to call Azure OpenAI by adding the
AzureGPTPipelineclass. - The prompt has been refined and modified to support multiple languages. Use
--languageargument for other language. (e.g.,--language Korean) - Made it possible to create questions only when necessary. A better strategy is to create questions and answers separately. Use
--question_onlyargument. (e.g.,--questioin_only True) - Prevented infinite loop.
mutate()in the original implementation determines the validity of the augmented statement and repeats the loop until it is valid. However, this process takes a very long time and there is a problem in that the loop repeats infinitely in certain situations.
How to create dataset
Option 1. If you want to generate your own seed dataset through this lab (Please check ../seed)
Example datasets are placed in this folder. Please try the minimal example first and configure your dataset by referring to the tunable parameters.
Debug for test
chmod +x run_debug.sh
./run_debug.sh
Option 2. If you already have your own dataset
Example datasets are placed in this folder. Please try the minimal example first and configure your dataset by referring to the tunable parameters.
Debug for test
python evolve.py --seed_file xxx.jsonl --column_names Instruction --num_rows 50 --max_len_chars 512 --language English
Tunable parameters
parser.add_argument("--seed_file", type=str)
parser.add_argument("--column_names", nargs='+', default="Instruction")
parser.add_argument("--num_rows", type=int, default=5)
parser.add_argument("--min_len_chars", type=int, default=32)
parser.add_argument("--max_len_chars", type=int, default=512)
parser.add_argument("--temperature", type=int, default=0.7)
parser.add_argument("--top_p", type=int, default=0.95)
parser.add_argument("--model_name", type=str, default="gpt-4o")
parser.add_argument("--language", type=str, default="English")
parser.add_argument("--question_only", type=bool, default=True)
Run example: