日本語でインデックスを検索した場合に、想定された検索結果になりません。例えば「ねこ」と検索すると「こねる」といったコンテンツも検索されてしまいます。
回答
想定された検索結果が表示されない場合、もしくは想定された検索スコアでない場合のよくある事象として、
検索文字列およびインデックスに格納された検索対象のコンテンツが、ご利用の言語 (日本語) に対して、適切にトークン化されていない可能性が考えられます。
以下のドキュメントにも記載があります通り、検索コンテンツの言語に対応した言語アナライザーが使用されないと想定外の検索結果になる場合があります。
存在するとわかっている用語でも一致数が 0 件なのはなぜですか?
よくあるケースは、クエリの型ごとにサポートされる検索ビヘイビアーと言語分析のレベルが異なることを把握していない場合です。 主要なワークロードである全文検索には、用語を原形に分解する言語分析フェーズが含まれています。 トークン化された用語は、より多くの数の変形と一致するため、このようなクエリ分析はより広い網を一致候補にかけます。
AI Search についてよく寄せられる質問
対処策としては、検索対象のインデックスのフィールドにて、検索コンテンツの言語に対応した言語アナライザーを設定し、インデックスを再構築することで、事象が解消する可能性があります。
以下の順番で詳細を記載します。
- ご利用の言語アナライザーでの検索文字列の字句解析結果の確認
- 言語アナライザーの選定
- 新しい言語アナライザーをインデックスのフィールドに設定する
1. ご利用の言語アナライザーでの検索文字列の字句解析結果の確認
まず、現状ご利用いただいている言語アナライザーの検索文字列に対する挙動を確認します。
一般的に AI Search のインデックスの検索時には、以下のドキュメントに記載の4つの手順が実行されます。
クエリの実行には次の 4 つの段階があります。
- クエリ解析
- 字句解析
- 文書検索
- ポイントの計算
2 番目の「字句解析」の段階では、検索文字列 (例えば「ねこ」) をインデックスのフィールドの言語アナライザーの設定値に応じてトークン化します。
例えばインデックスの content というフィールドの定義が以下のように "analyzer": "standard.lucene" なっていれば、言語アナライザーは standard.lucene というものになります。
インデックス作成時に特に明示的に言語アナライザーを指定しない場合は、standard.lucene となります。
1 | "fields": [ |
トークン化の挙動の確認については、ドキュメント アナライザーの動作テスト に記載がございます。
挙動確認には テキストの分析 (REST API Azure AI Search) を利用しますが、事前に AI Search サービスと、インデックスを用意し、認証のため API キーの取得 をしておく必要があります。
例えば「ねこ」が言語アナライザー standard.lucene によってどのように解析されるか確認するために、
以下のようにリクエストを送信します。
1 | # <searchName> にご利用の AI Search 名 |
応答は以下のようになります。「ねこ」が「ね」「こ」に分割されるため、
「ね」「こ」のそれぞれの検索でヒットした回数の合計が多いほど、検索上位に表示されるかたちになります。
「ねこ」という連続した文字列では検索されていない状況になります。
1 | { |
補足しますと、トークン化は検索時のみではなく、インデックスにデータを登録する際にも検索対象のコンテンツに対しても実行され、検索のためにインデックス内に保持されます。
検索対象のコンテンツがトークン化され、「ねこ」という単位のトークンが生成されれば、「ねこ」という文字列の検索にマッチすることになります。
2. 言語アナライザーの選定
この挙動を改善するには、検索に使用する言語に応じた言語アナライザーを利用します。
言語アナライザーは、各言語に対応したものが提供されております。
日本語の場合、ja.microsoft、ja.lucene が提供されております。
詳細はドキュメント サポートされる言語アナライザー をご確認ください。
言語アナライザーを日本語対応した ja.lucene としてトークン化を検証しますと、
1 | curl --location 'https://<searchName>.search.windows.net/indexes/<index-name>/analyze?api-version=2020-06-30' \ |
今度は以下のように「ねこ」が一語として認識されており、検索精度が向上することが期待されます。
1 | { |
3. 新しい言語アナライザーをインデックスのフィールドに設定する
言語アナライザーが選定できましたら、インデックスのフィールドに対して設定し検索時に利用できるようにします。
検索対象のコンテンツが格納されるフィールドの analyzer を ja.microsoft または ja.lucene として、
インデックスを再構築します。
1 | "fields": [ |
恐れ入りますが、以下のドキュメントに記載の通り、
言語アナライザーの変更にはインデックスの再作成が必要となりますのでご注意ください。
既存のフィールドのアナライザーを変更するには、インデックス全体を削除して再作成する必要があります (個々のフィールドを再構築することはできません)。
運用環境のインデックスの場合は、新しいアナライザーの割り当てを指定した新しいフィールドを作成することで再構築を延期し、古いものの代わりに使用を開始することができます。
アナライザーを追加する時期
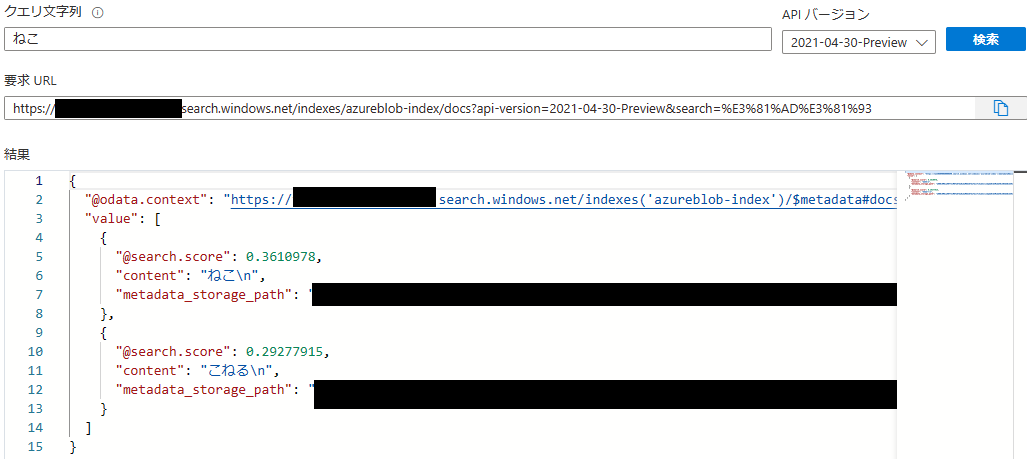
実際に検索の挙動を確認すると、インデックスのフィールドの言語アナライザーが standard.lucene の場合、
「ねこ」と検索すると、「こねる」といった別のコンテンツも検索結果に表示されてしまいます。
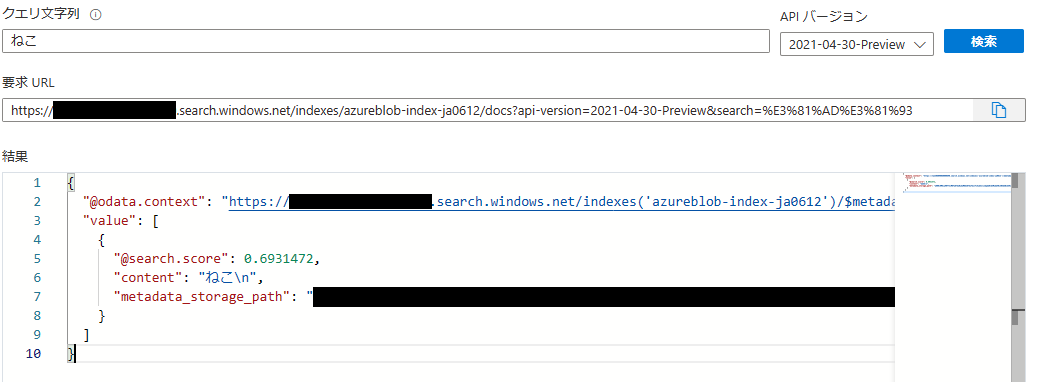
一方で、インデックスのフィールドの言語アナライザーが ja.lucene の場合、
「ねこ」を含むコンテンツのみが検索されており、想定された検索結果になっております。
参考ドキュメント
2024 年 04 月 09 日時点の内容となります。
本記事の内容は予告なく変更される場合がございますので予めご了承ください。
※本情報の内容(添付文書、リンク先などを含む)は、作成日時点でのものであり、予告なく変更される場合があります。