Run History
note
このコンテンツはお使いの言語では利用できません。
Azure ML can supercharge your ML workloads in (at least!) two ways:
- AML Compute: Providing powerful compute resoures to train larger models
- Run history: Best-in-class lineage and reproducability
In this article we focus on Run History - and why you need it in your life!
As teams progress to running dozens, and eventually hundreds of experiments, having some way to organize them is essential. Run History is a service that provides a number features that quickly become essential to your ML-model builders:
Experiments and Runs#
When you are running dozens of experiments in multiple different projects, having a clear
way to organize and search though the results is key. Azure ML provides two concepts to help
with this: Runs and Experiments.
Runs#
A run is a single execution of your code - usually a training script. The run has a life-cycle: the code is prepared to be submited to Azure ML (e.g. via a ScriptRunConfig), then the code is submitted
Once the code is submitted to Azure ML (for example, via a ScriptRunConfig) a Run object is
created. This compute target is prepared (nodes are provisioned, containers hosting your Python
environment are fired up), the entry point script is called ($ python run.py [args]) and logs
start being generated:
You may log metrics to Azure ML with run.log('<metric_name>', metric_value) and monitor them in the studio:
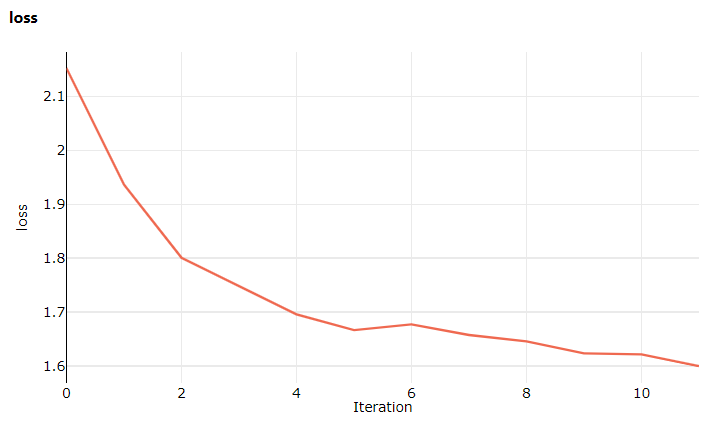
The training concludes, usually some model files are saved, and the nodes are released.
But the story doesn't end there. The run persists even after the nodes are returned to Azure. You can always return, either in code or via the studio, to see a history of your runs, all their outputs and metrics, and the exact code that was used to generate them.
Experiments#
An Experiment is a collection of runs. All runs belongs to an Experiment. Usually an Experiment is tied to a specific work item, for example, "Finetune Bert-Large", and will possess a number of runs as you iterate toward this goal.
Snapshot#
When you submit your code to run in Azure ML, a snapshot is taken. This is a copy of the exact code that ran. Think of this as version control for your experiments. Want to reproduce the results from that experiment 2-months ago even though you've iterated on the model and the training script in the meantime? No problem, snapshot has you covered!
You have total control of what goes into the snapshot with the .amlignore file. This plays
the same role as a .gitignore so you can efficiently manage what to include in the snapshot.
Metrics#
As you run experiments, you track metrics - from validation loss through to GPU load. Analysing these metrics is essential to determining your best model. With Run History, these metrics are stored for all your runs.