splunk-enterprise
| :exclamation: Please note that this repository is not being actively maintained and some of the information may be out of date (including VM SKU versions). | |—————————————–|
Introduction
This documentation provides detailed guidance to support the deployment of Splunk Enterprise on Azure in line with Splunk Validated Architectures and the following key priorities:
- High Availability
- Maximum Performance
- Security
- Scalability
Table of Contents
- Introduction
- Splunk Architecture
- High Availability & Disaster Recovery
- Infrastructure Sizing
- Deploy Splunk Enterprise on Azure reference implementation
Splunk Architecture
Core Components
This section describes the core Splunk Enterprise components and relevant Azure-specific guidance including recommended VM families. Core Splunk Enterprise components include Indexers, and Cluster Master, Search Heads and Search Head Deployer, Monitoring Console and License Master.
Indexers & Cluster Master
An Indexer is the Splunk Enterprise component that indexes data; transforms raw data into events and writes them to disk. The Indexer also performs searches against indexed data in response to search requests. Splunk Indexer Virtual Machines (VMs) can be deployed as an Indexer Cluster to enable horizontal scalability and high availability of the Indexer component. The Cluster Master is the Splunk Enterprise instance that manages an Indexer Cluster. The Cluster Master manages configuration for the Indexers and also manages replication of data between clustered nodes and sites to ensure that the number of copies of data in the cluster meets the search and replication factors.
It is recommended to deploy Splunk Indexer Clusters across 3 Availability Zones for maximum availability, providing a financially backed SLA of 99.99% uptime of the Indexer cluster. It is recommended to set both Indexer Replication Factor and Search Factor to at least 3, with one copy per site. It is also recommended to assign each Indexers site according to Availability Zone of the Indexer VM, for more information on Splunk’s site concept please refer to Splunk’s documentation. This ensures that each Availability Zone contains a searchable copy of all indexed data.
This reference architecture recommends two VM families for Indexers, the general-purpose Dds_v4 family or the storage-optimized Ls_v2 family. The characteristics of these VM types are summarized below:
The Ls_v2 family features very high throughput, low latency, directly mapped local NVMe storage which is ideally suited to Splunk hot/warm storage disks due to the high IOPS and throughput. This makes the Ls_v2 family the preferred option where storage performance is paramount. As these are locally attached ephemeral disks, data will be lost if you de-allocate your VMs or there is a platform-initiated redeployment of the VM to an alternative host in the event of a failure. The replication of data across three Availability Zones provides data durability, however simultaneous failures across all Availability Zones could theoretically result in permanent data loss.
The Dds_v4 family is the latest general-purpose Azure VM family offering well priced compute for general purpose workloads. If managed disks are attached for Splunk hot/warm and cold storage, these can offer better data durability in the case of a platform-initiated redeployment of the VM due to a failure. However, the Premium Managed Disks storage will not offer the same high IOPS or ultra low latency as the locally attached NVMe disks with the Ls_v2 family. This makes the Dds_v4 family the preferred option where data durability is the overriding priority.
The documentation for both of the VM families should be reviewed via the links above to fully understand the VM characteristics prior to implementing Splunk Enterprise in production to ensure you select the most appropriate SKU to meet your performance and availability requirements.
As a general guide, the Ls_v2 family is appropriate if your Splunk search profile is mostly storage-bound. If your search profile is CPU-bound, the Dds_v4 family is likely the preferred choice due to the more recent CPU generation. For an explanation of search characteristics and performance implications please see the Splunk documentation on this topic.
When considering Cluster Master availability, please note that if the Cluster Master is not available the data indexed in the Indexer cluster will still be fully available and replicated. In the event of an Indexer failure whilst the Cluster Master is inaccessible, data availability may be impacted until the Cluster Master is restored. For more details on the impact of a Cluster Master failure please refer to the Splunk documentation.
A single Cluster Master VM in one Availability Zone with Premium SSD disks will have a financially backed SLA of 99.9%. For higher availability requirements, you can deploy a second standby Cluster Master in a different Availability Zone, this will provide a financially backed SLA of at least 99.99%. This will require a failover mechanism, for example updating the DNS record of the Cluster Master to target the standby instance.
The recommended VM family for the Cluster Master is the general-purpose Dds_v4 family.
The Splunk Enterprise on Azure reference implementation deploys an Indexer cluster with a configurable number of Indexer VMs evenly distributed across 3 Availability Zones for maximum availability and data durability. For this reason the minimum Indexer count supported by the deployment template is 3 and the chosen region to deploy to must have a minimum of 3 Availability Zones. The VM family and SKU is configurable in line with the recommendations documented above. The configurable deployment parameters are described below, however there is one notable difference in the storage configuration based on the chosen VM SKU:
- Dds_v4 - The hot/warm disk size per instance, and corresponding Splunk Indexer Volume, is configurable up to the maximum supported Premium SSD size (currently 32 TB)
- Ls_v2 - The hot/warm disk size per instance is determined by striping all local NVMe disks associated with the selected SKU. With the largest VM SKU, L80s_v2, this is 10x1.92TB for a total usable capacity of 19.2TB per instance
In addition to the Indexer instances a Cluster Master VM will be deployed and pre-configured to manage the Indexer cluster. The Cluster Master VM SKU within the recommended Dds_v4 family is configurable as needed.
Please note that the web server port for the Cluster Master has been updated to 8001 in the reference implementation to prevent cookie overwrite issues associated with sharing a single frontend host/backend port combination.
Search Heads & Search Head Deployer
A Search Head is the Splunk Enterprise instance that handles search management functions, directing search requests to the Indexers and then serving the results back to the user. The Search Head Deployer (or Deployer) is the Splunk Enterprise instance that applies a consistent configuration baseline to all Search Head Cluster members.
It is recommended to deploy Splunk Search Head Clusters across 3 Availability Zones for maximum availability, providing a financially backed SLA of 99.99% uptime of the Search Head cluster. We recommend setting the Search Head replication factor to the Splunk default value of 3 to ensure availability of search artifacts.
When considering Search Head Deployer availability, it is worth noting that if the Search Head Deployer is not available the Search Head cluster functionality will not be impacted, however cluster-wide configuration changes cannot be applied to the Search Head cluster. For this reason the Search Head Deployer typically does not need to be highly available; having a recovery plan for re-deploying the Search Head Deployer may be sufficient. Keeping the Search Head Deployer configuration in source control is advisable and will ensure that the Search Head Deployer can be recovered without loss of configuration.
The recommended VM family for the Search Heads and the Search Head Deployer is the general-purpose Dds_v4 family.
The Splunk Enterprise on Azure reference implementation deploys a Search Head cluster with a configurable number of Search Head VMs and configurable SKU within the Dds_v4 family. The minimum number of Search Head VMs which can be deployed is 3, as this is the minimum requirement for a stable Search Head cluster which is resilient against the loss of a single Search Head VM (see Splunk documentation for more details) and ensures that the Search Head cluster VMs are spread over 3 Availability Zones for maximum availability.
In addition to the Search Heads, the Splunk Enterprise on Azure reference implementation will deploy a Search Head Deployer to distribute Search Head configuration bundles. The Search Head Deployer VM SKU is configurable within the Dds_v4 family.
The Search Head cluster is deployed behind an Application Gateway for HTTP(S) access to the Splunk UI and load balancing of search traffic. Each Search Head VM as well as the Search Head Deployer VM are deployed with a P30 Premium Managed Disk mounted at /opt, the Splunk install location.
Monitoring Console
The Monitoring Console is a specific Search Head instance with a set of dashboards, platform alerts and health checks enabled, which provide insight into a deployment’s performance and resource usage.
In deployments with a Search Head cluster Splunk does not recommend enabling the Monitoring Console on the Search Head cluster but instead having a separate Search Head VM which runs the Monitoring Console, or co-located with the Cluster Master in smaller environments.
The Splunk Enterprise on Azure reference implementation deploys a standalone Search Head to run the Monitoring Console. The Monitoring Console instance is deployed behind an Application Gateway for access to the Splunk UI, this means that if Monitoring Console were to be unavailable it could easily be re-deployed behind the same frontend IP and users could continue to access it via the same URL.
Please note that the web server port for the Monitoring Console has been updated to 8003 in the reference implementation to prevent cookie overwrite issues associated with sharing a single frontend host/backend port combination.
License Master
The License Master manages Splunk licensing for all connected components and consolidates data on license usage across the Splunk environment.
High availability is typically not required for a License Master. If the License Master is unavailable the Splunk deployment will continue to function for 72 hours before there would be any impact. It is advisable to create a recovery plan to rebuild the License Master and all configuration within this grace period.
Optional Components
This section describes the optional Splunk Enterprise components and relevant Azure-specific guidance including recommended VM families. Optional Splunk Enterprise components include Deployment Server, Heavy Forwarders, HTTP event collectors and Syslog receivers.
Deployment Server
A Deployment Server is a Splunk Enterprise instance which acts as a centralised configuration manager for non-clustered Splunk components such as Universal or Heavy Forwarders. While not required, a Deployment Server can simplify managing non-clustered Splunk instances and is included in the Splunk Enterprise on Azure reference implementation.
The recommended VM family for the Deployment Server is the general-purpose Dds_v4 family.
The Splunk Enterprise on Azure reference implementation deploys a load balancer to manage deployment clients calls to the Deployment Server. Additional Deployment Server instances can be added to the load balancer backend pool based upon availability and scale requirements, for example if a large number of deployment clients are being maintained.
Please note that the web server port for the Deployment Server has been updated to 8002 in the reference implementation to prevent cookie overwrite issues associated with sharing a single frontend host/backend port combination.
Heavy Forwarders
Splunk recommends the use of Universal Forwarders where possible with Heavy Forwarders deployed only when there is a specific requirement such as certain Technical Add-ons as described below. Heavy Forwarders should not be used as an intermediate forwarding or aggregation tier. For more details please refer to this Splunk blog post.
Technical Add-ons which pull data from other sources, such as non-Splunk APIs, will likely need to be deployed on a Heavy Forwarder. This is because the Splunk Universal Forwarder is not shipped with Python, which is typically used in Technical Add-ons for making API calls. A Splunk Heavy Forwarder is simply a full instance of Splunk Enterprise which is configured to forward data to the Indexers. Please check the documentation for the specific Technical Add-on intended for use to confirm if it can be deployed on a Universal Forwarder or requires a Heavy Forwarder. For more details on the differences between Heavy Forwarders and Universal Forwarders please refer to the Splunk documentation on types of forwarders.
The recommended VM family for the Heavy Forwarders is the general-purpose Dds_v4 family.
HTTP Event Collectors
For receiving events pushed via HTTP, Splunk recommends using their HTTP Event Collection (HEC) capability, which is available in the full Splunk Enterprise instance. Although this can technically be enabled on any Splunk Enterprise VM, the Splunk recommendation is to enable HEC on the Indexer cluster as this simplifies the architecture and will improve data distribution. For more details on the pros and cons of HTTP Event Collection architectures please refer to the HEC Toplogy Choices section of Splunk Validated Architectures.
In line with Splunk guidance, the Splunk Enterprise on Azure reference implementation currently supports enabling HEC on the Indexers and also includes a Load Balancer for high availability.
Syslog Receivers
If there is a requirement to ingest syslog data into Splunk, a syslog receiver will be required. For high availability in larger environments, Splunk recommends using Splunk Connect for Syslog, a container based solution for collecting syslog messages and forwarding to their HTTP Event Collector.
The recommended VM family for Syslog Receivers is the general-purpose Dds_v4 family.
The Splunk Enterprise on Azure reference implementation supports optionally deploying syslog receiver nodes, running Splunk Connect for Syslog which is configured to forward logs to the HTTP Event Collector. If syslog receivers are required, HTTP event collection must be enabled.
Networking
Network Architecture
When designing the Virtual Network address space for Splunk, consideration should be given to potential future growth in order to ensure that the network has enough IP addresses to accommodate additional Splunk Enterprise VMs. The Splunk Enterprise on Azure reference implementation requires at least a /23 size network. This is then segmented into the below subnets:
| Subnet | Components |
|---|---|
| Search | Search Head VMs |
| Indexers | Indexer VMs |
| Forwarders | Heavy Forwarder and Syslog Receiver VMs |
| Management | VMs for Cluster Master, Search Head Deployer, Deployment Server and License Master |
| Azure Bastion | Subnet for Azure Bastion to enable remote console access to private VMs |
| Application Gateway | Subnet for Application Gateway to enable HTTP access to Splunk components |
This subnet separation allows Network Security Groups to be implemented to restrict communication between components to the required protocols and ports, reducing the risk of lateral movement in the event that a publicly available component becomes compromised.
The high level network architecture and traffic flows are illustrated below.

Public Access
It is strongly recommended to implement Splunk Enterprise on Azure with private IPs only, except where access is required over public networks such as end user access to Search Heads or external services sending data via the HTTP Event Collector. Where public access is required this should be via appropriate ingress or load balancing solutions for security and high availability purposes, for example:
- HTTP Event Collector with Public Load Balancer
- Search Heads, Monitoring Console, other management components with Application Gateway
Where public access is implemented Network Security Groups should be applied to limit access to approved sources only, to prevent direct access to Splunk Enterprise VMs from the public internet.
The supplied Splunk Enterprise on Azure reference implementation deploys all VMs with private IP addresses only by default. This can be overridden to provision public IPs on a per-component basis, for example to simplify access to a test/development environment. It is not recommended to enable direct access to Splunk VMs via the public internet for security and privacy reasons unless you have an explicit requirement to receive Splunk data directly from public networks.
The Splunk Enterprise on Azure reference implementation deploys an Application Gateway for access to the Splunk UI on the Search Head cluster, Deployment Server, Monitoring Console and Cluster Master. By default, this will not be publicly accessible and there is an option to limit access to a specific source IP range. There is a deployment parameter to enable public access if this is required. It is recommended that a TLS listener with a valid certificate is configured on the Application Gateway.
In addition, a Standard Load Balancer will be provisioned if HEC is selected at deployment time. This provides an option to expose a public IP for HEC data without directly exposing Indexer VMs to the public internet.
Azure Bastion
When implementing Splunk Enterprise on Azure without VM public IP addresses Azure Bastion can be used for secure, browser-based console access for remote administration and management purposes. More information is available in the Azure Bastion documentation. To ensure all instances are reachable regardless of private network connectivity, the Splunk Enterprise on Azure reference implementation will deploy Azure Bastion by default when deployed without VM public IP addresses.
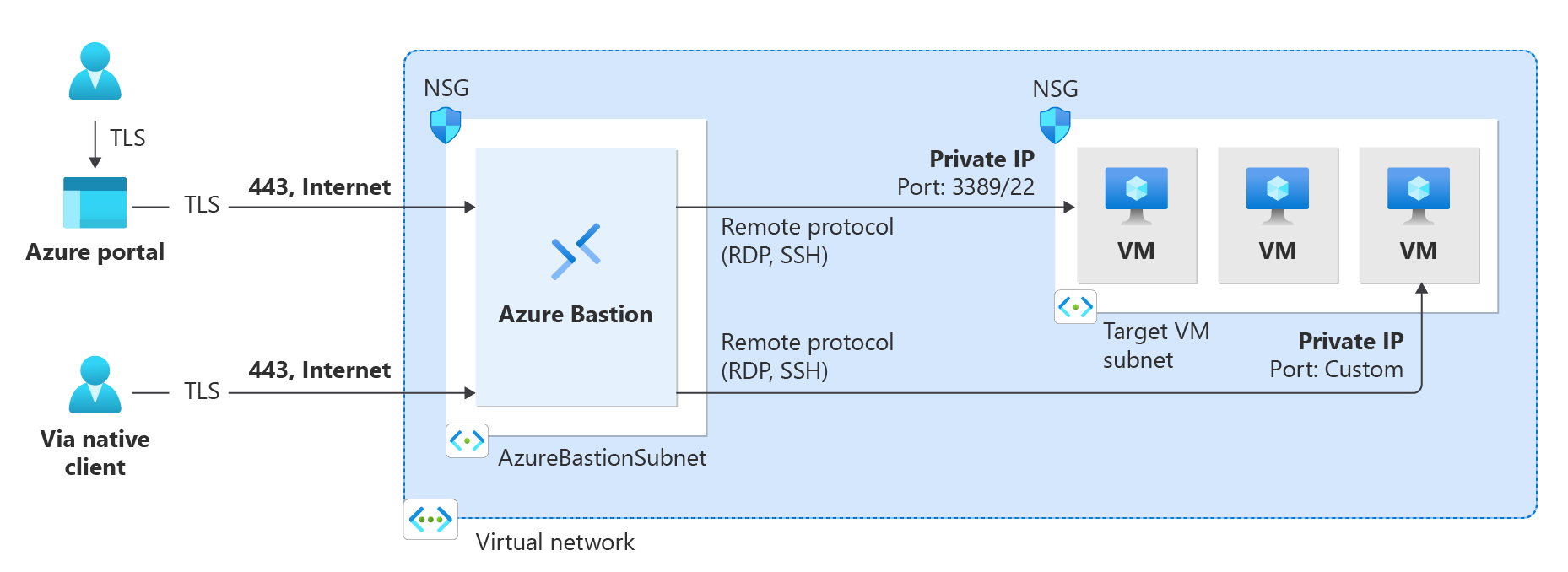
Private Connectivity Considerations
One implication of using Private IPs only is that the Indexers will not be accessible via the public internet; this will mean that data cannot be sent via Splunk to Splunk protocol over the internet. If there is a requirement to send data from Universal Forwarders to the Indexer VMs via public internet connectivity, the Indexer VMs will need to have Public IPs. The use of a network load balancer to load balance Splunk to Splunk traffic is not supported. This only applies to unparsed data being sent from one Splunk component to another. HTTP Event Collector traffic can, and should, be sent via a load balancer for high availability.
If there is a requirement to send data from on premises to Splunk Enterprise in Azure via either ExpressRoute or VPN, consideration will need to be given on how to allow the flow of traffic from the virtual network where ExpressRoute or your VPN terminates to the Splunk virtual network. This could be achieved most easily by peering the two virtual networks. The same approach can be used for sending data from other virtual networks in Azure to Splunk.
A common pattern to achieve this connectivity is a hub-spoke network topology, please see Azure hub-spoke reference architecture for more information. A generic illustration of this architecture, not including Splunk Enterprise components, is shown below.

Outbound Connectivity
One implication of using internal load balancers for the Indexers (HEC), Deployment Server and Syslog Receivers is that outbound access via the Load Balancer will not be possible. Outbound access is required for installing and configuring Splunk (and syslog-ng in the case of the Syslog Receivers). Because of this, the Splunk Enterprise on Azure reference implementation will deploy a separate external Load Balancer to enable outbound access for the Indexers, Deployment Server and Syslog Receiver VMs if an internal Load Balancer is selected for access. This is in line with Azure best practises.
DNS Resolution
All Splunk VMs should be resolvable via DNS to simplify service to service communication without any dependency on IP addresses. This also offers the flexibility to replace components configured with DNS host names without reconfiguring Splunk. DNS can also be used for load balancing connections to Indexers from Universal Forwarders or Heavy Forwarders.
The supplied Splunk Enterprise on Azure reference implementation creates a private DNS zone and automatically registers records for all VMs. These DNS records are referenced in all Splunk component configuration, ensuring that if a VM is rebuilt or replaced for any reason, the corresponding DNS record can be updated without requiring changes to Splunk configuration. The DNS zone name is configurable with a deployment parameter. For production deployments records can be added to your existing DNS servers in addition, or in place of, the supplied private DNS.
High Availability & Disaster Recovery
All clustered components such as Indexer and Search Head instances should be deployed across 3 Availability Zones for maximum availability and data durability. The Splunk Enterprise on Azure reference implementation provides this by default with no option to override.
When considering the availability of non-critical management components or those that do not offer a native HA configuration (Deployment Server, Monitoring Console, Cluster Master and Search Head Deployer) it is key that a proven recovery plan is in place in the event of component failure. This could take the form of a standby instance of each component or a proven redeployment and restore process. All Splunk configuration and knowledge objects should be persisted in a source control repository with appropriate backup and recovery processes.
Infrastructure Sizing
The infrastructure requirements for Splunk Enterprise are determined by a number of factors, some of which are described below with links to additional guidance from Splunk.
Compute Sizing
Splunk’s Capacity Planning Manual can help sizing the compute that your Splunk deployment will require. Splunk compute sizing depends on:
- Daily ingestion volume
- Volume of indexed data
- Number of concurrent users
- Number of scheduled searches/reports
- Type of searches
Splunk Storage Sizing
Splunk offer a sizing calculator for calculating storage requirements based on expected daily ingest volume and retention. If an existing platform is deployed the raw compression factor and metadata size factor can be adjusted for a more accurate estimate of how well Splunk data will be compressed.
If the Ls_v2 VM family are used as Indexers, the local NVMe disks are used as the hot/warm disk, and the size of hot/warm storage available will be defined by size of the available local disk as described earlier in this documentation.
Deploy Splunk Enterprise on Azure reference implementation
Pre-Requisites
- Ensure that the selected region has a minimum of 3 Availability Zones.
- Ensure that the VM core quotas on the subscription are sufficient for the family and quantity of VMs you plan to deploy.
- Ensure the Splunk installer .tgz file for the planned version of Splunk Enterprise is available as a publicly accessible URL. Note that the Splunk Enterprise on Azure reference implementation has been tested and is fully compatible with Splunk versions, 7.3, 8.0, 8.1 (other versions may be compatible but this has not been tested and confirmed).
- Ensure that a valid Splunk license file for the required daily ingest volume is available.
Deployment Steps
Click the button below to launch the deployment experience in the Azure Portal. All configuration items are documented below for reference purposes, in addition to tooltips provided in the Azure Portal.
Once the deployment is completed successfully, the outputs of the deployment will contain the appropriate URLs to access the Splunk UI for the Search Head cluster, Monitoring Console, Cluster Master and Deployment Server.
Basics
| Option Name | Default | Description |
|---|---|---|
| Subscription | no default | Azure subscription for deployment |
| Resource Group | no default | Resource group within the selected subscription to deploy to or create a new resource group |
| Region | East US | Azure region to deploy to |
Networking
| Option Name | Default | Description |
|---|---|---|
| Virtual Network | splunk (10.1.0.0/16) | The name, size and address space for the virtual network that will be created for Splunk resources. This should be at least a /23 size network |
| Indexer Subnet | indexers (10.1.0.0/24) | The name, size and address space for the indexer subnet within the Virtual Network. This should be at least a /25 size subnet |
| Search Subnet | search (10.1.1.0/24) | The name, size and address space for the search head subnet within the Virtual Network. This should be at least a /24 size subnet |
| Management Subnet | management (10.1.2.0/24) | The name, size and address space for the indexer subnet within the Virtual Network. This should be at least a /25 size subnet |
| Forwarder Subnet | forwarder (10.1.3.0/24) | The name, size and address space for the forwarder subnet within the Virtual Network. If Heavy Forwarders are deployed they will be deployed in this subnet. This should be at least a /24 size subnet |
| Azure Bastion Subnet | AzureBastionSubnet (10.1.4.0/27) | The name, size and address space for the Azure Bastion subnet within the Virtual Network. This will be required if the VMs are deployed without private IPs. This should be at least a /24 size subnet |
| Application Gateway Subnet | ApplicationGatewaySubnet (10.1.5.0/28) | The name, size and address space for the Application Gateway subnet within the Virtual Network. The Application Gateway for access to the Splunk UI will be deployed in this subnet. This should be at least a /24 size subnet |
| Provision Azure Bastion Service | Yes | Whether to provision Azure Bastion service. |
| Source CIDR block for Splunk UI | 0.0.0.0/0 | Source IPs to allow for access to the Splunk UI |
| Source CIDR block for SSH access to VMs | 0.0.0.0/0 | Source IPs to allow for SSH access to the VMs |
General VM Settings
| Option Name | Default | Description |
|---|---|---|
| Preferred Linux Distribution | Ubuntu 18.04 LTS | The Linux distribution that VMs will be deployed with. Supported distributions are Ubuntu 18.04, CentOS 7.7, RHEL 7.6 PAYG (which can be switched to BYOS after deployment, please follow these instructions) |
| User name | no default | The username used for all VMs |
| SSH Public Key | no default | SSH public key for access to VMs |
Splunk General
| Option Name | Default | Description |
|---|---|---|
| Splunk user name | splunkadmin | The username used for the initial Splunk admin user |
| Splunk Password | no default | The password used for the initial Splunk admin user. This should contain at least one number, upper case and lower case letter and symbol |
| Splunk pass4SymmKey | no default | The pass4SymmKey used when configuring Splunk clustering. This should contain at least one number, upper case and lower case letter and symbol |
| Splunk license file | no default | The Splunk license to be installed on the License Master |
| Splunk Enterprise Installer URL | no default | Provide a publicly accessible endpoint where your chosen Splunk version can be downloaded, such as an Azure storage account. The file should be in .tgz format |
| License Master Server Size | D16ds_v4 | The VM SKU for the License Master |
| Deployment Server Size | D16ds_v4 | The VM SKU for Deployment Server |
| Provision Deployment Server VM Public IP | No | Whether to deploy Deployment Server VM with a Public IP |
| Provision Deployment Server Load Balancer Public IP | No | Whether to deploy Deployment Server Load Balancer with a Public IP |
| Monitoring Console VM Size | D16ds_v4 | The VM SKU for Monitoring Console |
| Provision Monitoring Console VM Public IP | No | Whether to deploy Monitoring Console VM with a Public IP |
Indexer Configuration
| Option Name | Default | Description |
|---|---|---|
| Cluster Master Size | D16ds_v4 | The VM SKU for the Cluster Master |
| Provision Cluster Master VM Public IP | No | Whether to deploy Cluster Master VM with a Public IP |
| Number of Indexers | 3 | Number of indexers to be deployed in the Indexer cluster |
| Indexer Size | D64ds_v4 | The VM SKU for the Indexers |
| Hot/Warm Volume Size | 1024 TB | The size of the hot/warm disk on each Indexer. This will only be selected if the Indexer VM SKU does not have a suitable local disk |
| Cold Volume Type | Standard HDD | The type of disk to use for the cold volume on each Indexer |
| Cold Volume Size | 1024 TB | The size of the hot/warm disk on each Indexer |
| Number of indexing pipelines | 2 | Number of ingest pipelines on the Indexers |
| Cluster-wide replication factor | 3 | The Indexer cluster replication factor |
| Cluster-wide search factor | 2 | The Indexer cluster search factor |
| Provision Indexer VM Public IPs | No | Whether to deploy Indexer VMs with Public IPs |
| Configure HTTP Event Collection on Indexers | No | Whether to configure HTTP Event Collection on the Indexers, this will be enabled if syslog receivers are required |
| Use Public IP for HTTP Event Collection | No | Whether to deploy the HTTP Event Collection Load Balancer with a Public IP |
Search Head Configuration
| Option Name | Default | Description |
|---|---|---|
| Number of Search Heads | 3 | Number of Search Heads to be deployed in the Search Head cluster |
| Search Head Size | D64ds_v4 | The VM SKU for Search Heads |
| Provision Search Head VMs Public IP | No | Whether to deploy Search Head VMs with a Public IPs |
| Search Head Deployer Size | D16ds_v4 | The VM SKU for Search Head Deployer |
| Provision Search Head Deployer VM Public IP | No | Whether to deploy Search Head Deployer VM with a Public IP |
Forwarder Configuration
| Option Name | Default | Description |
|---|---|---|
| Provision Heavy Forwarders | No | Whether to deploy Heavy Forwarders |
| Number of Heavy Forwarders | 3 | Number of Heavy Forwarders to be deployed |
| Heavy Forwarder Size | D8ds_v4 | The VM SKU for Heavy Forwarders |
| Number of pipelines per Heavy Forwarder | 2 | Number of ingestion pipelines for the Heavy Forwarders |
| Provision Heavy Forwarder VM Public IP | No | Whether to deploy Heavy Forwarders VM with a Public IP |
| Provision Syslog Receivers | No | Whether to deploy Syslog Receivers |
| Number of Syslog Receivers | 3 | Number of Syslog Receivers to be deployed |
| Syslog Receivers Size | D8ds_v4 | The VM SKU for Syslog Receivers |
| Source CIDR block for Syslog forwarding | 0.0.0.0/0 | Source IPs to allow for syslog forwarding to the Syslog Receiver VMs |
| Provision Syslog Receiver VMs with Public IP | No | Whether to deploy Syslog Receiver VMs with Public IPs |
| Provision Syslog Receiver Load Balancer with Public IP | No | Whether to deploy Syslog Receiver Load Balancer with a Public IP |
Tags
| Option Name | Default | Description |
|---|---|---|
| Name | no default | Tag name |
| Value | no default | Tag value |
| Resource | Select all | Which resources to apply the tag to |