※本記事は Azure OSS Developer Support ブログ Container Apps: Troubleshooting and configuration with Health Probes の日本語抄訳版です。
Container Apps サポート担当の谷津です。
この投稿では、Container Apps でホストされているアプリケーションに正常性プローブを使用する場合のトラブルシューティングと構成について説明します。
Azure Container Apps は Kubernetes 上に構築されているため、Kubernetes に存在する機能と概念的に非常に密接にマップされた Container Apps 機能がかなり多くあります。
そのうちの 1 つが正常性プローブで、pod の移動が発生したときや、正常に実行中のアプリケーションで時間の経過とともに、アプリケーションの正常性を判断する優れた方法です。これらの正常性プローブは Kubernetes 正常性プローブ
の上に構築されているため、Kubernetes の公式ドキュメントを読むと、知見が深まる可能性があります。
正常性プローブは、コンテナーの起動時のタイムアウト、コンテナー実行時のデッドロック、コンテナーがトラフィックを受け入れる準備ができていない場合のトラフィックの処理に関連するパフォーマンスの問題を回避するのに役立ちます。
以下では、Container Apps に関する一般的なプローブ情報と、いくつかのトラブルシューティング シナリオについて説明します。
注: 全体として、プローブ構成をいろいろ試したうえでアプリケーションに必要な最適な設定とユースケースを確認することをお勧めします。
リクエストのフロー
プローブは、一般的な Kubernetes (kubelet) と同様に、Container Apps 環境内から発生します。これは、イングレスを介して送信されるブラウザーやその他のアプリケーションなどの外部クライアントからのリクエストとは別のフローです。
プローブのメカニズムと制約事項
サポートされているメカニズムは次のとおりです。
- HTTP(s) と TCP
現在の制限は次のとおりです。
- gRPC、名前付きポート、および exec コマンドはサポートされていません。こちらをご覧下さい
- コンテナごとに追加できるプローブの種類はプローブの種類(liveness/readiness/startup)毎に 1 つだけです。
HTTP プローブが成功したと見なされるには、設定されたエンドポイントからの応答が HTTP 200 から HTTP 399 の間である必要があります。
構成
デフォルト設定
アプリケーションでイングレスを有効にする場合、Container Apps プラットフォームには、既定の TCP 正常性プローブ構成が設定されています。公開ドキュメントについては、こちらを参照してください。TCP プローブで設定されるポート (Port) は、イングレスのポートとして指定されたポートに設定されます。
このため、Log Analytics の ContainerAppSystemLogs_CL テーブルには、さまざまなプローブ メッセージが表示される場合があります(デフォルトでプローブが設定されるため)。プローブは、pod の正常性を判断する Kubernetes (ならびに Container Apps の拡張機能) の機能の一部です。
正常性プローブを明示的に有効にしていない場合に、 [Containers (コンテナー)] > 対象のコンテナーを選択 > [Health Probes (正常性プローブ)] ブレードを表示すると、次のように表示されます。
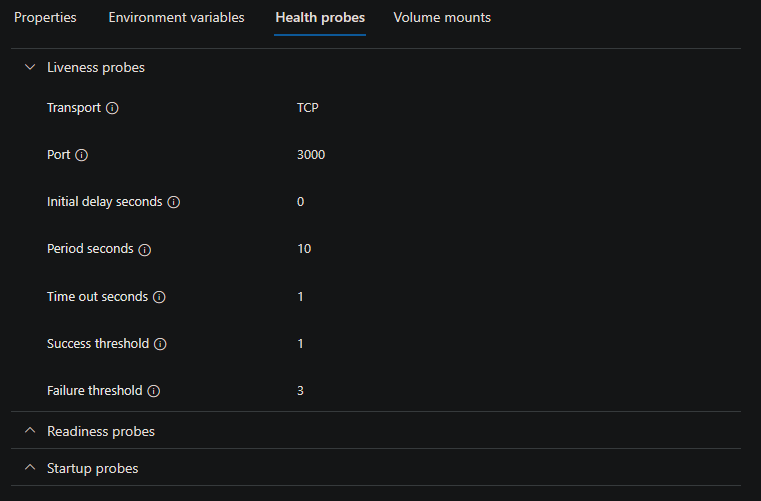
TCP over HTTP が設定される理由は、TCP が推定される公開ポート (プローブ設定自体で特に設定されていない限り、イングレスを有効にするときに設定されるポート) のみをチェックするためです。HTTP が使用されていた場合、アプリケーションに ping を実行するために “推測” されたルートは、200 から 400 以外の HTTP ステータス コードを返す可能性があるため、常にコンテナーに失敗が表示されます。
一般的な構成
HTTP(s) と TCP の正常性プローブは、Container Apps の “Containers (コンテナー)” セクション内の “Health Probes (正常性プローブ)” セクションで構成されます
正常性プローブの構成スキーマとサポートされている設定については、この例を参照してください。さらに、プローブ メカニズムとして HTTP を使用する場合は、正常性状態を確認するロジックを含むアプリケーション コード内に HTTP エンドポイントを実装する必要があります。こちら に例を示します。
TCP 正常性プローブの場合、アクセス可能なポートがあなたの Dockerfile の中で exposed されているべきです。
リクエストヘッダーと User-Agent
HTTP 正常性プローブ用に Kubelet によって送信される既定の user-agent とヘッダーは、こちらで定義されています - Kubernetes - HTTP probes。
これをプログラムで確認したい場合は、リクエストヘッダーを console/stdout/stderr にログ出力できます。これは、ContainerAppConsoleLogs_CL で確認可能です。
たとえば、node.js では、req.headers を console.log(req.headers) のようにログ出力します。Kubelet によって実行されるプローブのヘッダーは、次のようになります。
1 | { |
host: ポッドの IP アドレスと一致する必要があります - このアドレスのポートは、既定の正常性プローブまたは使用されている場合はイングレス ポートで構成されている必要があり、正常性プローブまたは明示的に使用されている場合は、上記の正常性プローブの種類に設定されたポートである必要があります。user-agent: これは、クラスターで使用されているバージョンと一致する必要があります。これはKubeletによって設定されます。
このヘッダーは、正常性プローブの [追加設定] セクションにカスタム ヘッダーを追加することでオーバーライドできます。目的のエージェント名の値を持つキーをUser-Agentで追加します。
HTTPS プローブ
各種ランタイムでの HTTP および HTTPS プローブの使用例のソース コード例については、 azureossd - container-apps-health-probe-examplesを参照してください。
HTTPS プローブを設定する必要がある場合は、アプリケーションもしくはコンテナが HTTPS トラフィック用に設定されたサーバー経由のトラフィックを受け入れる必要があります。また、HTTP トラフィックと HTTPS トラフィックの両方を受け入れるアプリケーションを実行できます。
こちらは最初にローカル環境でテストを行い、これが Container Apps でも動作することを検証できます。自己署名証明書を生成してこれらを使用し、https://localhost:<port> 上でテストすることができます。
Python と Gunicorn の例は以下です。HTTP と HTTPS の両方のトラフィックを受け入れています。
1 | gunicorn -b 0.0.0.0:8000 app:app --timeout 600 --access-logfile "-" --error-logfile "-" & \ |
これらのプローブは Kubernetes プローブに基づいているため、ここで説明するように証明書の検証はスキップされ、自己署名証明書からの警告も無視する必要があります。
アプリケーションが HTTPS 経由でリッスンするように適切に構成されていない場合は、正常性プローブから Connection Refused もしくは Get "https://x.x.x.x:<port>/": http: server gave HTTP response to HTTPS client が発生します。
注: これにより、リビジョンが失敗として表示されますので、詳細については以下のトラブルシューティングの項を参照してください。
トラブルシューティング
ログ分析クエリ
正常性プローブ関連のメッセージは、ContainerAppSystemLogs_CL で確認できます。
これは、ポータルのコンテナー アプリの [ログ] ブレードで実行する必要があります。これらのメッセージのほとんどは、正常性プローブに直接関連するものの場合、警告またはエラー関連の情報のみが表示されます。成功したプローブが呼び出されるたびに表示されるわけではありません。
次の表は、この表に表示される出力の例です - TCP と HTTP の両方の正常性プローブのエラーがこの表に表示されます。
1 | Liveness probe failed: HTTP probe failed with statuscode: 500 |
プローブが HTTP 正常性プローブの指定されたパスにヒットしたときにログ出力される stdout/stderr がある場合、これは ContainerAppConsoleLogs_CL にログ出力されます
指定したエンドポイントに対してプローブ要求がいつ開始されたかを知る場合、最も簡単な方法は、関連するアプリケーションのエンドポイントのロジックに何らかのコンソール出力または print ステートメントを追加することです。
プローブが失敗しているときに見られる動作
プローブが指定された基準で 200 から 399 の間のステータスコードを返さない場合、または指定されたポートにアクセスできない場合、これは失敗として表示されます。表示される内容は使用されているプローブによって異なります。
ポータル
この動作は、HTTP(s) プローブと TCP プローブの両方で表れます。
注:以下で解説されているリビジョンの失敗に関する表示では、プロビジョニングと実行のステータスが更新されるまでに数分かかる場合があります。さらに、「失敗」に変わる前に短い期間だけ「成功」と表示される場合があります。
liveness (稼働): 失敗している liveness プローブ は、失敗したプローブがあるリビジョンの [リビジョン] ブレードに次のように表示される場合があります。

[概要] ブレードでは、リビジョンは次のように失敗と表示されます。

startup (スタートアップ): 失敗しているスタートアッププローブは、失敗したプローブがあるリビジョンの [リビジョン] ブレードに次のように表示される場合があります。

[概要] ブレードでは、リビジョンは次のように失敗と表示されます。

readiness (準備): 失敗している readiness プローブは、失敗したプローブがあるリビジョンの [リビジョン] ブレードに次のように表示される場合があります。

[概要] ブレードでは、リビジョンは次のように失敗と表示されます。

liveness プローブと startup プローブはコンテナの再起動に失敗し続けますが、readiness プローブは実行を継続し、pod で障害が発生したコンテナを明示的に再起動しません。
この動作は、Kubernetes - Configure Probes
で解説されています。このドキュメントによって振舞の違いを理解することができます。
外部
失敗したリビジョンの FQDN にアクセスしようとすると、Envoy から stream timeout エラーが表示されることがあります。
一般的なエラー
Connection refused
これはさまざまな理由で発生する可能性があり、必ずしも実際のエラーを示しているわけではありません。例えば、これは通常、コンテナーが pod で開始しているときに表示されます。
新しいリビジョンを作成する Container Apps の更新、ポッドやレプリカの移動など、多数のイベントによってこのエラーはトリガーされる可能性があります。このような場合はノイズと見なすことができます。
また、デフォルトのプローブは TCP を使用しており、TCP プローブが一般的に使用されているめ、通常、デフォルトプローブ が有効な場合にも見られます。
コンテナーが TCP ポートからのリクエストを受け入れる準備がまだ整っていない場合は、接続が例えば以下のように拒否されます。
Startup probe failed: dial tcp 100.100.0.18:3000: connect: connection refused
同様な問題は、実際にはリストされていない、もしくは公開されていない指定された HTTP ポートでも発生する可能性がありますが、根本的には異なる問題ならびに原因です(以下で説明します)。
TCP プローブは、pod の IP と公開されているコンテナーのポートで ping を実行します。このチェックは Kubernetes - Pod Lifecycle - チェックメカニズム で呼び出されます。
HTTP(s) プローブは、pod の IP とポートで、指定されたパス (存在する場合) とともに ping を実行します。TCP プローブには、パスを指すオプションはありません。
これは、特にデフォルト設定を使用している場合や、「Initial delay seconds (初期遅延秒数)」が非常に低い値に設定されている場合に発生する可能性があります。
独自のプローブを指定しない場合、Startup、Liveness、および Readiness TCP プローブのデフォルトの「初期遅延秒数」は 1 秒です。また、最小の0秒も許容値です。こちらを踏まえると、connection refused メッセージを表示したくない場合は、「初期遅延秒数」をより長い値に設定してみてください。
起動が遅いアプリケーションを確認する場合は、Startup プローブを使用することで Liveness プローブと Readiness プローブの実行開始を延期する方法、または initialDelaySeconds を同様に Startup プローブと組み合わせる方法をて使用することができます。
connection refused のように表示される実際の問題は、HTTP(s) または TCP プローブポートを、アプリケーションコンテナによって実際には公開されていないポートに設定した場合です。例えば、アプリケーションがポート 3000 のみを公開しているが、HTTP プローブのポートが 3001 に指定されている場合などです。
Liveness probe failed: Get "http://100.100.0.37:3001/probe/http": dial tcp 100.100.0.37:3001: connect: connection refused
pod が単に起動中のために発生する connection refused メッセージとは対照的に、ここにはいくつかの重要な違いがあります。
- 起動中の pod とコンテナに関連する
connection refusedの場合と比較すると、これは数回しか表示されない場合があり、その後、ポッドは実行中として表示され、アプリケーションがアクセス可能になります。 - HTTP(s)/TCP プローブに正しくない/公開されていないポートが設定されている場合、このメッセージが表示され続けることがあります。最終的に、リビジョンは「失敗」状態として表示されることがあります
HTTP プローブではパスを設定する必要があるため、HTTP ポートのエラーメッセージと TCP ポートのエラーメッセージは何らかの方法で区別できます。例えば、公開されていないポートを対象とする HTTP プローブが以下であるように、何らかの方法で区別できます (このようにして、正常性プローブは失敗します)。
Startup probe failed: Get "http://100.100.0.53:3001/": dial tcp 100.100.0.53:3001: connect: connection refused
一方で、以下は同じ問題を抱えている TCP である可能性があります。
startup probe failed: connection refused
プローブがステータスコード 404 で失敗しました
HTTP プローブのいずれかにて statuscode: 404 で失敗することがあります。ContainerAppSystemLogs_CLには以下のように表示されます。
1 | Readiness probe failed: HTTP probe failed with statuscode: 404 |
プローブの失敗による影響は、Log Analytics の ContainerAppSystemLogs_CL テーブルで記録されさます。
1 | Container some-container failed startup probe, will be restarted |
トラブルシューティング:
- 404 を返す指定されたパスが実際に存在するかどうかを確認して確認します
- サイトが公開されている場合は、アプリケーションの FQDN にアクセスし、指定されたパスを追加して、404 が返されるかどうかを確認できます。
- これが存在しないパスに設定されている場合は、アプリケーションが 200 から 399 のステータス コードを返す必要があるので、ドキュメントを確認してください。
- 一部のランタイム(たとえば、.jar を使用している組み込み Tomcat、または war を実行している Tomcat)では、404 は実際にはアプリケーション関連のエラーを示す可能性があります。これは nginx の場合も同じです。その場合は、
ContainerAppConsoleLogs_CLもしくはアプリケーションログを確認して、書き込まれているアプリケーションに stderr があるかどうかを確認します。
プローブがステータスコード 500 で失敗しました
設定可能な HTTP プローブのいずれかに HTTP probe failed with statuscode: 500 が表示される場合があります。ContainerAppSystemLogs_CLには以下のように表示されます。
1 | Readiness probe failed: HTTP probe failed with statuscode: 500 |
プローブの失敗による影響は、Log Analytics の ContainerAppSystemLogs_CL テーブルで呼び出されます。
1 | Container some-container failed startup probe, will be restarted |
トラブルシューティング:
500 が継続的に発生する場合は、指定されたエンドポイントのロジックを確認します。HTTP 500 は通常、アプリケーション エラーを示します。
まだ実装されていない場合は、指定されたエンドポイントにログを追加します (特に、様々なテストのために外部呼び出しを行ったり、内部ロジックを実行したりするロジックがある場合)。このログは
ContainerAppConsoleLogs_CL内に表示されます。例として、500をスローする存在しないエンドポイントへの呼び出しを次に示します。
const res = await axios.get("https://g00gle.com")すると、
ContainerAppConsoleLogs_CLにAxiosError: getaddrinfo ENOTFOUND g00gle.comが表示されます。このコンソールへのログ記録を実装し、正常性プローブに指定されたパスのロジックを理解しておくと、トラブルシューティングを迅速化できます。
プローブがステータスコード 502 で失敗しました
設定可能な HTTP プローブのいずれかに HTTP probe failed with statuscode: 502 が表示される場合があります。ContainerAppSystemLogs_CLには以下のように表示されます。
1 | Readiness probe failed: HTTP probe failed with statuscode: 502 |
プローブの失敗による影響は、Log Analytics のContainerAppSystemLogs_CLテーブルで記録されます。
1 | Container some-container failed startup probe, will be restarted |
トラブルシューティング:
- 指定されたプローブ エンドポイントのロジックを確認します。他の依存関係(アウトバウンド)があるかどうか、およびそれらが到達可能かどうかを確認します。
- ステータスコードの返却がエンドポイントのロジックで処理されているかどうかを確認します。
注: 事前定義された内部タイムアウトの後に Web サーバーにこれを実行させる代わりに、アプリケーション コードを介して 502 (またはその他のステータス コード) を返すことは可能です。
プローブが失敗しました: http: サーバーが HTTPS クライアントに HTTP 応答を返しました
表示されるメッセージ全文は、Liveness probe failed: Get "https://xxx.xxx.x.xx:xxxx/some/path": http: server gave HTTP response to HTTPS client です。
基本的に、このエラーは、HTTPS リクエストを受け入れないパスに HTTPS プローブが指定されたことを意味します。ほとんどのアプリケーションランタイムとそれに関連するサービスでは、HTTPS リクエストを受け入れるには、これを適切に有効にするための証明書を使用してサーバーを設定する必要があります。
問題の理解:
- アプリケーションで実際に HTTPS サーバーが有効になっていることを確認します。ほとんどのランタイムと Web サーバーでは、HTTP サーバーと HTTPS サーバーの両方を同時に実行するように指定したり、1 つのサーバーで HTTP リクエストと HTTPS リクエストの両方を処理できるようにしたりできます
- Web サーバーが HTTPS 用に適切に設定されていることを確認します。これはローカルで簡単に検証できるため、最初にアプリケーションが HTTP と HTTPS の両方でローカルに実行できることをテストすることをお勧めします。
- 自己署名証明書を使用している場合、証明書の使用に関する「警告」がブラウザに表示されることがありますが、これはバイパスでき、localhost は HTTPS 経由でアクセスできます。
注: 上記の「HTTPS プローブ」セクションで説明したように、Kubelet は証明書の検証をスキップするため、自己署名証明書を使用できます。
3501/v1.0/healthz の接続が拒否されました
このメッセージは、[some probe] failed: Get "http://xxx.xxx.xx.xx:3501/v1.0/healthz": dial tcp xxx.xxx.xx.xx:3501: connect: connection refused を表します。
これが表示される場合は、Dapr が有効になっている場合にのみ表示されます。「接続が拒否されました」というメッセージは、Dapr が有効になっている場合における、Dapr サイドカー コンテナーへのプローブ用です。これが表示される場合、通常はポッドの移動またはその他のアクティビティがある場合です。そのため、このメッセージは通常はノイズであり、一般的には問題を示すものではありません。
2023 年 11 月 28 日時点の内容となります。
本記事の内容は予告なく変更される場合がございますので予めご了承ください。
※本情報の内容(添付文書、リンク先などを含む)は、作成日時点でのものであり、予告なく変更される場合があります。