※本記事は Azure OSS Developer Support ブログ Container Apps and Failed Revisions の日本語抄訳版です。
Container Apps サポート担当の谷津です。
この投稿では、Container アプリの “リビジョン” が “Failed (失敗)” と表示される理由について、より一般的なシナリオについて説明します。
Container Apps の導入により、リビジョンの概念が導入されました。リビジョンを使用すると、アプリケーションのさまざまな「バージョン」を管理できます。この概念は、基本的に Kubernetes と同じ考え方に従います。リビジョンとそのモードの詳細については、こちらのリンクを参照してください。
リビジョンの “Failed” は、次のようなシナリオで表示される場合があります。
- 環境への最初の Container Apps のデプロイ。
- 既存の Container Apps に対する変更 (
templatesセクションの下の構成など) により、新しいリビジョンを作成した場合。 - 既存の Container Apps から新しいリビジョンを作成し、新しいリビジョンに対して変更または更新を行った場合。
これらのシナリオは、複数の理由で発生する可能性があることに注意することが重要です。アプリケーションコードの問題、コンテナの設定ミスなど。以下では、いくつかのシナリオについて説明します。
イングレスが正しくない
アプリケーションを Container Apps にデプロイし、外部イングレスを使用する場合、targetPort は Dockerfile で公開されているポート (またはアプリケーションがリッスンしているポート) と一致する必要があります。
これが正しく設定されていない (例えば Target Port を 80 に設定してアプリケーションが 8000 でリッスンしている)場合、最初にデプロイするとき、または新しいリビジョンを作成して更新するときに、リビジョンが失敗します。
例えば、このアプリケーションはポート 8000 でリッスンするようにデプロイされていますが、ターゲット ポートとして 80 が設定されています。
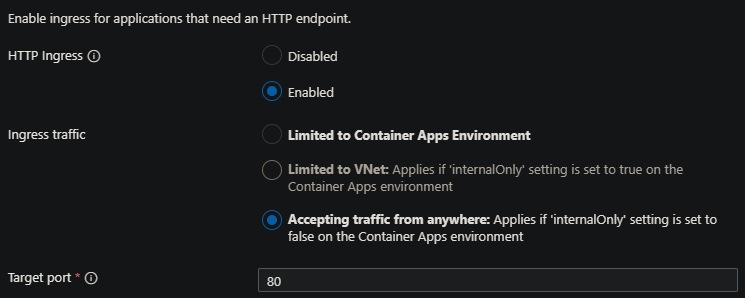
ポートが一致していないことが原因でコンテナは応答を正常に返さないため、リビジョンが Failed (失敗) としてマークされていることがわかります。

この場合の解決策は、Target port を Dockerfile で公開されているもの(またはアプリケーションがリッスンしているポート)に設定することです。
重要: アプリケーションをバックグラウンド サービスとして実行している場合や、HTTP トラフィックをリッスンする予定がない場合は、コンテナーから HTTP 応答が返されて正常性を判断する必要があるため、Ingress を有効にしないでください。このタイプのシナリオでは、リビジョンが Failed (失敗) としてマークされる原因にもなります。
正常性プローブ
正常性プローブは、コンテナーの正常性を 3 つの異なる方法 (スタートアップ、準備、稼動) で判断するように構成できます。これらが正しく構成されていない場合、またはアプリケーションがこれらの設定に応答しない場合、リビジョンは Failed (失敗) としてマークされます。例えば、
- 準備 (Readiness) プローブで間違った
Portの設定を行っている。 - 200 - 400 の範囲外の応答を返すパス (例: 404) を 準備プローブで設定している。
- 稼働 (Liveness) プローブに対して上記のいずれかを実行している。
- アプリケーションが HTTP トラフィックを想定していない場合は、コンテナから HTTP 応答が返されないため、リビジョンの失敗を引き起こす可能性があるため、これを無効にする必要があります。
注: これは、コンテナーが無期限にプロビジョニングされていることを示している場合もあります

特権コンテナーの実行
特権コンテナは実行できません。これにより、リビジョンが失敗します。プログラムが実際の root アクセスを必要とするプロセスを実行しようとすると、コンテナ内のアプリケーションでランタイムエラーが発生し、失敗します。
注: コンテナ内のユーザー「root」は、通常、ホスト上の権限のないユーザーにマッピングされ、最終的には非特権コンテナとして実行されることに注意してください。Docker 自体が設計上デフォルトで特定の CAP_ Capability Key を削除し、ユーザー名前空間が機能しているという事実によるものです。
さらに、Azure Container Apps で docker run.. <args> を実行するための方法は仕様上無いと共に、Kubernetes に設定された特権を変更するためのオプションも公開されていません。
アプリケーションエラー
Docker イメージがビルドされてレジストリに push された場合、この push に含まれる変更や tag のイメージが Azure Container Apps の新しいリビジョンで使用されます。こちらの点を考慮してください。
例えば、アプリケーションを実行すると、上記のようなシナリオの後、Log Analytics ワークスペースに次のように表示されます。
Error [ERR_MODULE_NOT_FOUND]: Cannot find package 'dotenv' imported from /app/server.js
このようなアプリケーションの問題により、コンテナが終了し、リビジョンが失敗します。 基本的に、コンテナの終了 (プロセスの終了) の原因となる未処理の例外またはエラーは、失敗したリビジョンとして表示されます。
これらのシナリオでは、Log Analytics、
Container App 固有のテーブル、Azure CLI、またはログ ストリームを使用して、アプリケーションがこれを引き起こしているかどうかを検証できます。
注: コンテナーに障害が発生している場合、ログ ストリームに出力が表示されない可能性があることに注意してください。その場合は、Log Analytics を使用して、アプリケーションが stdout/err に書き込んでいるかどうかを再確認します。
無効なオプションまたはアクセス不能なレジストリ
image/tagの値
image と tag の組み合わせが間違っている、または正しくない場合、リビジョンが失敗する可能性もあります。
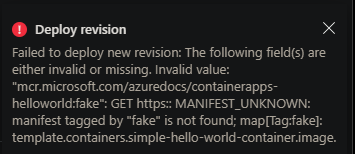
ただし、ほとんどの場合 (デプロイ方法によって異なります)、このステージの前に検証が失敗します。例えば、ポータルを使用してこれを行うと、次のようになります。
ポータル:
テンプレートでのデプロイ:
{"status":"Failed","error":{"code":"DeploymentFailed","message":"At least one resource deployment operation failed. Please list deployment operations for details. Please see https://aka.ms/DeployOperations for usage details.","details":[{"code":"BadRequest","message":"{\r\n \"code\": \"WebhookInvalidParameterValue\",\r\n \"message\": \"The following field(s) are either invalid or missing. Invalid value: \\\"mycontainerregistry.azurecr.io/container-apps-scaling-examples-http:latest2\\\": GET https:: MANIFEST_UNKNOWN: manifest tagged by \\\"latest2\\\" is not found; map[Tag:latest2]: template.containers.containerappsscalingexampleshttp.image.\"\r\n}"}]}}
このシナリオが当てはまると思われる場合は、imageと tag の組み合わせが有効であることを確認してください。
ネットワーク環境
続いて、構成ミスまたは環境の問題 (ファイアウォールがコンテナー レジストリへのアクセスをブロックしている、レジストリへの DNS lookup が失敗している、などのネットワーク環境) が原因でイメージの pull に失敗した場合、イメージ自体が正常に pull されないため、リビジョンの失敗として表示される可能性があります。
このシナリオでは、これをパブリックに pull できるかどうかを確認し、可能な場合は逆算して環境のトラブルシューティングを行います。
以下のドキュメントは、設定のヘルプとして確認できます。
- ネットワーク - アーキテクチャの概要
- 外部環境でのデプロイ
- 内部環境でのデプロイ
- カスタム VNET のセキュリティ保護
- VNET を使用する場合のお客様の責任 ※(日本語抄訳版補足): 原文のリンクが既に切れているためリンクなし
リソース競合
例えば、継続的に大量の CPU やメモリを消費するアグレッシブなスケール ルールやアプリケーションは、これらのワークロードを実行している Pod のアプリケーションをクラッシュさせる原因となる可能性があります。
内部的には、これらをプロビジョニングするためにリソースの割り当てが試みられますが、発生するシナリオが常に大量のリソースを使用している場合 (メモリなど、構成されている Container Apps の pod の上限に達している場合)、ワークロードのプロビジョニングに失敗する可能性があります。
このようなシナリオでは、 [監視] の [メトリック] ブレードを使用して、要求、レプリカ数、CPU、メモリなどのメトリックを確認できます。
アグレッシブなスケーリングが行われる場合は、これらのルールイベントをトリガーしているものに関する基準を確認します。
2023 年 11 月 16 日時点の内容となります。
本記事の内容は予告なく変更される場合がございますので予めご了承ください。
※本情報の内容(添付文書、リンク先などを含む)は、作成日時点でのものであり、予告なく変更される場合があります。